从“闪电”到“先锋”:Gemini 3.5 Flash 凭什么是全球首款“原生智能体”小模型?
前言:如果说 2025 年是大模型的“参数内卷年”,那么 2026 年则是“Agent 爆发年”。在刚刚结束的 Google I/O 2026 上,所有人的目光都聚焦在那个曾经被视为“廉价版”的系列——Gemini 3.5 Flash。这一次,Google 彻底撕掉了 Flash “低配”的标签。
一、 重新定义“思考”:不仅仅是 CoT,而是 API 级的深度博弈
很多极客会反驳:“原生思维链(CoT)不是早就在 Gemini 底层支持了吗?”
没错,但 Gemini 3.5 Flash 的革命性在于,它首次将“思考”的黑盒交到了开发者手中。在最新的 API 规范中,Google 引入了 thinkingLevel 参数和 ThinkingConfig 对象。
这意味着,开发者可以像拨动音量旋钮一样,精准控制模型的推理深度:
- minimal:极速响应,适合高频指令。
- medium:平衡模式。
- high:全力推理,模型会在输出第一位 Token 前进行深度逻辑博弈。
配合 IncludeThoughts: true 参数,开发者可以直接在 API 回包中捕获模型那“隐秘的思考过程”。这种“思考透明化”是构建可调试、高可靠智能体(Agent)的基石。
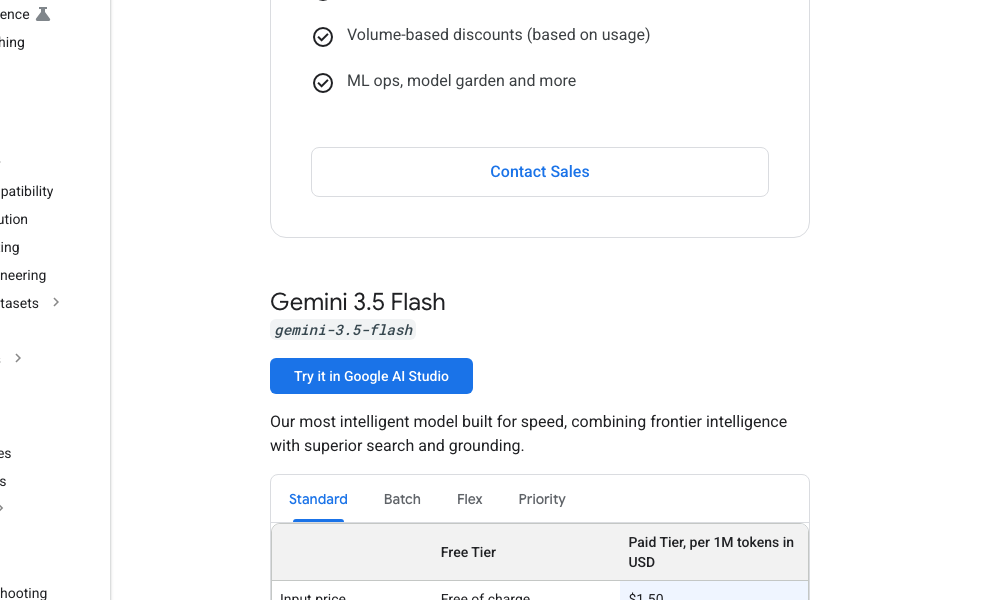 图注:在 1M 上下文量级下,$1.50 的输入定价让“暴力推理”成为了可能。
图注:在 1M 上下文量级下,$1.50 的输入定价让“暴力推理”成为了可能。
二、 硬核 Benchmarks:它在“解决问题”,而不仅仅是“对话”
在 I/O 现场,Google 抛出了两个让全场肃然起敬的指标:Terminal-Bench 2.1 (76.2%) 和 MCP Atlas (83.6%)。
我们要看懂这两个跑分的含金量:
- Terminal-Bench:这不再是 MMLU 那种选择题。它要求模型在真实的 Linux 终端环境下,自主执行 Git 操作、调试复杂的 Python 依赖报错。76.2% 的得分意味着,它在处理真实开发任务时,成功率已经逼近了去年的旗舰 Pro 模型。
- MCP Atlas:这是衡量模型对 Model Context Protocol (MCP) 协议支持深度的关键。在多智能体协作场景下,Gemini 3.5 Flash 能以极高的成功率调用跨平台的工具,成为 Agent 集群中的“协作中枢”。
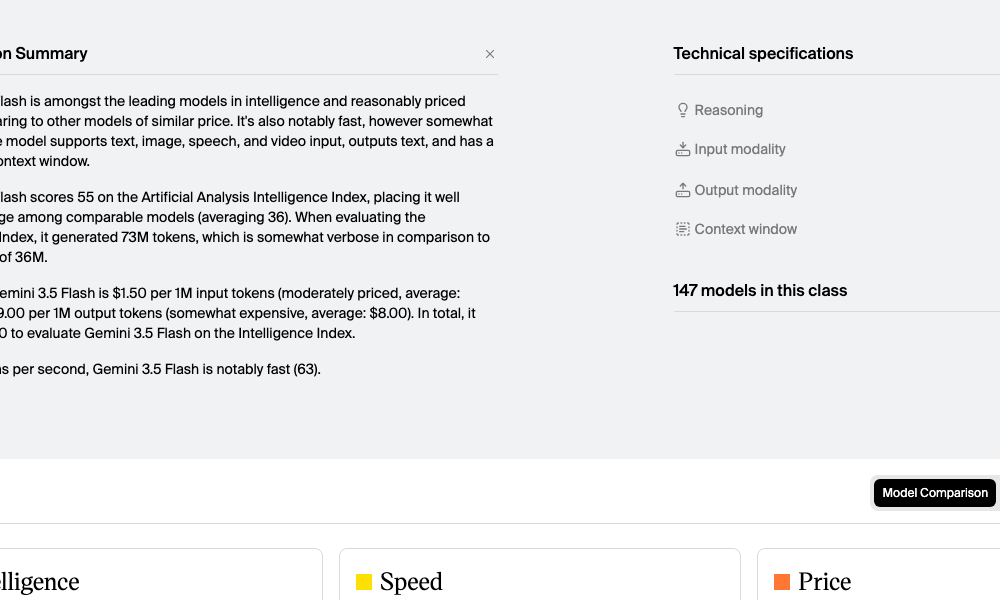 图注:根据 Artificial Analysis 评估,Gemini 3.5 Flash 的 Intelligence Index 达到了 55,远超同价位段 36 的平均水平。
图注:根据 Artificial Analysis 评估,Gemini 3.5 Flash 的 Intelligence Index 达到了 55,远超同价位段 36 的平均水平。
三、 性能怪兽:4倍 TPS 与“智商密度”
如果说智商是“高度”,那么 TPS(每秒输出 Token 数)就是“加速度”。
Gemini 3.5 Flash 在输出速度上实现了 4倍于前代旗舰 的爆发式提升。在 Agentic Workflow 中,每一步思考的延迟都会被多级协作放大,Flash 级的高吞吐量让原本需要 30 秒的复杂决策缩短到了 8 秒以内。
这种**“智商密度”**(单位成本下的推理能力)的质变,直接将 AI 从“搜索增强”推向了“行动增强”。
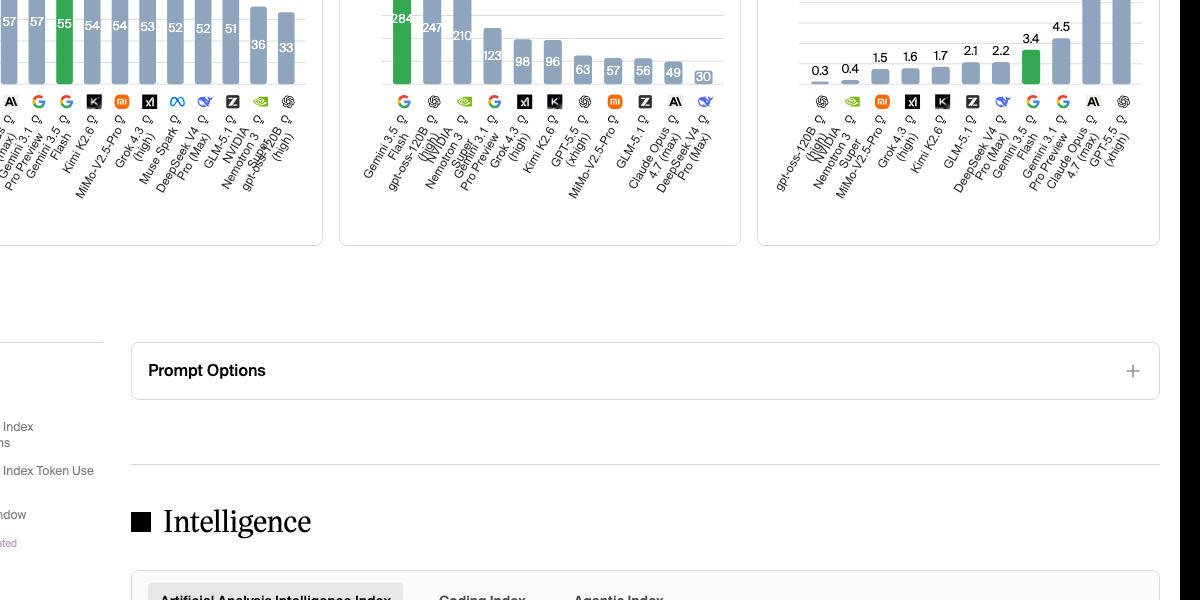 图注:在智商-速度象限图中,Gemini 3.5 Flash 稳稳占据了“最高效”象限。
图注:在智商-速度象限图中,Gemini 3.5 Flash 稳稳占据了“最高效”象限。
四、 总结:开发者为何必须关注 3.5 Flash?
Google 的意图非常明显:把最贵的推理能力,做成最廉价的工业燃料。
Gemini 3.5 Flash 不是在做减法,而是在做“特化”。它精准切中了智能体时代的三个痛点:
- 低成本长上下文:1M 窗口足以吃下整个项目文档。
- 可控推理深度:通过 API 参数控制延迟。
- 极速工具调用:原生支持 MCP,天生为 Agent 而生。
对于国内开发者而言,3.5 Flash 的发布意味着我们可以用极低的预算,构建出具备“深思熟虑”特质的智能应用。
参考资料:
- Google Developer Blog: I/O 2026 Announcement
- Artificial Analysis: Gemini 3.5 Family Deep Dive
- Gemini API Docs: Thinking Config Guide