深度拆解 Gemini 3.5 Flash:Google 把旗舰级智能塞进了一道"闪电"
Google I/O 2026 刚落幕。没有 Ultra,没有万亿参数的军备竞赛——今年的绝对主角,是一个"小"模型:Gemini 3.5 Flash。
它在 LLM Stats 排行榜上直接空降第六,速度是 GPT-5.5 的 2.5 倍,价格却只有它的三分之一。
这是什么概念?相当于一辆思域跑出了保时捷的圈速,还只要思域的油钱。
一、I/O 现场:Google 今年憋了什么大招?
2026 年 5 月 19 日,Sundar Pichai 站在 Shoreline 舞台上,用一句话定义了 Gemini 3.5 系列:
“Frontier intelligence with action.”
翻译成人话就是:不光聪明,还能干活。
 Google DeepMind Gemini 产品页。来源:deepmind.google
Google DeepMind Gemini 产品页。来源:deepmind.google
这次发布一共三件事:
- Gemini 3.5 Flash — 当天即可用,速度怪兽,“Flash 级价格,Pro 级脑子”
- Gemini 3.5 Pro — 还在内测,6 月放出,主打极限推理
- Gemini Spark — 全新 24/7 AI 管家,能帮你发邮件、做调研,你关了电脑它还在后台干活(是的,你没看错)
今天咱们聚焦那道"闪电"——Gemini 3.5 Flash。
二、先看参数:一张表,看懂 3.5 Flash 的全部底牌
“Talk is cheap, show me the numbers.”
| 参数 | Gemini 3.5 Flash |
|---|---|
| 上下文窗口 | 1,000,000 Tokens(一百万。不是 128K,不是 200K,是一百万。) |
| 输入价格 | $1.50 / 百万 Token |
| 输出价格 | $9.00 / 百万 Token(含思考 Token) |
| 缓存价格 | 读写 $0.15/M(正常价的一折) |
| 输入模态 | 文本、图片、视频、音频、PDF 全都吃 |
| 输出速度 | 475 tok/s(LLM Stats 实测) |
| LLM Stats 综合排名 | #6 / 300+ 模型(59.0 分) |
| Artificial Analysis 智能指数 | #7 / 147 模型(55 分) |
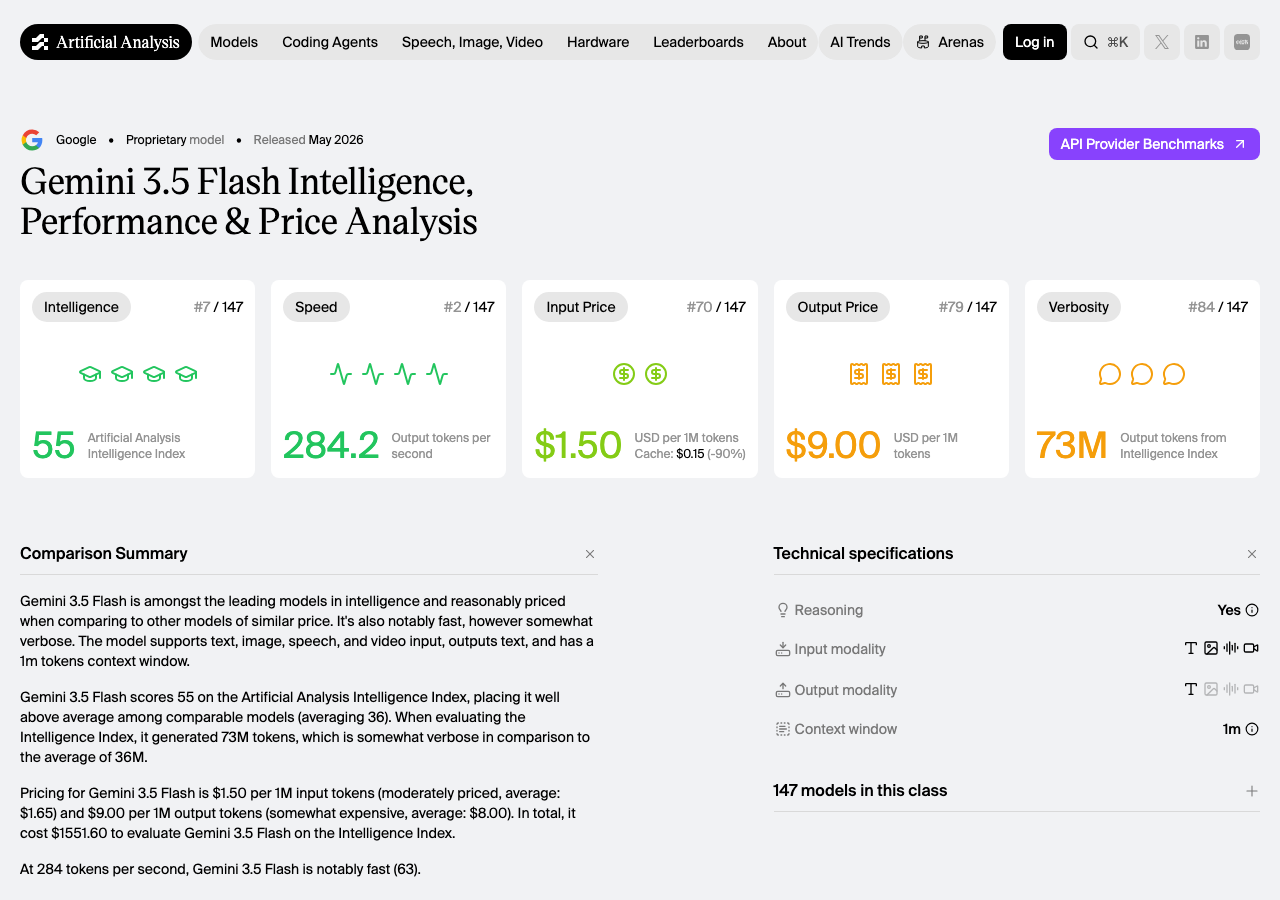 Artificial Analysis 独立评估卡片。Intelligence 55, Speed 284 tok/s, 输入 $1.50, 输出 $9.00。来源:artificialanalysis.ai
Artificial Analysis 独立评估卡片。Intelligence 55, Speed 284 tok/s, 输入 $1.50, 输出 $9.00。来源:artificialanalysis.ai
给不想看数字的朋友翻译一下:
- 💰 有多便宜? 你拿一整本《计算机程序设计艺术》(约 100 万 Token)扔给它分析,输入成本是 1.5 美元,大约 10 块钱人民币。一杯奶茶钱。
- ⚡ 有多快? 475 个 Token/秒。你眨一下眼睛的时间(约 300 毫秒),它已经吐出 140 个 Token 了。大约半页 A4 纸的文字。
- 🧠 有多聪明? LLM Stats 排行榜全球第六,综合能力超过了自家上一代旗舰 Gemini 3.1 Pro。相当于"实习生干翻了老员工"。
三、Benchmark:不吹不黑,逐项拆
Google 官方秀的成绩单
| 基准测试 | 得分 | 一句话说明 |
|---|---|---|
| Terminal-Bench 2.1 | 76.2% | 在真实 Linux 终端里写代码、调 Bug、搞 CI/CD |
| MCP Atlas | 83.6% | 多步骤工具调用,Agent 协作能力 |
| CharXiv Reasoning | 84.2% | 看懂论文里的图表并推理 |
一个细节:Google 这次刻意没提 MMLU、HumanEval 这些"老基准"。为啥?因为 2026 年了,前沿模型在这些测试上都考到 90 分以上,区分度已经不大了。就像你不会用"能不能打字"来区分两台笔记本电脑。
所以 Google 换了赛道——考的全是"干活能力":你能不能在终端里独立写代码?能不能调用多个外部工具完成复杂任务?能不能看懂一篇 Nature 论文里的数据图?
Terminal-Bench 76.2% 是什么概念?100 个真实开发任务——Git merge 冲突、Python 依赖地狱、Shell 脚本调试——它能独立搞定 76 个。GPT-5.5 的成绩是 78.2%,也就差了两道题。
MCP Atlas 83.6% 更值得关注。MCP(Model Context Protocol)是 Anthropic 在 2025 年提出的 AI 工具调用标准,现在已经是行业事实标准。3.5 Flash 在这个基准上号称超过了 Claude Opus 4.7 和 GPT-5.5。对于想搭 Agent 系统的开发者来说,这可能是最重要的一个数字。
四、第三方数据:排行榜上见真章
自己说自己牛不算数,得看独立评测。
Artificial Analysis:智能指数 55,排名 #7
Artificial Analysis 是目前最受认可的 AI 模型独立评测平台之一。他们的评价:
“Gemini 3.5 Flash is amongst the leading models in intelligence and reasonably priced. It’s also notably fast, however somewhat verbose.”
翻译:聪明、便宜、快——但话多。
“话多"这个评价挺有意思的:3.5 Flash 在评测中产出了 73M token 的输出,而平均水平只有 36M。它的冗长度是同行的两倍。在实际使用中你可能需要在 System Prompt 里多加一句"简洁回答"来驯服它。
| 维度 | 数值 | 排名 | 一句话 |
|---|---|---|---|
| 智能指数 | 55 | #7/147 | 远超平均分 36 |
| 速度 | 284 tok/s | #2/147 | 仅次于极轻量模型 |
| 输入价格 | $1.50/M | #70 | 比均价便宜一丢丢 |
| 输出价格 | $9.00/M | #79 | 略贵(均价 $8.00) |
| 话多程度 | 73M tokens | #84 | 是平均的两倍 |
LLM Stats:全球第六,这才是真正的炸裂
如果说 Artificial Analysis 的数据让人眼前一亮,那 LLM Stats 的排行榜直接让人坐不住了:
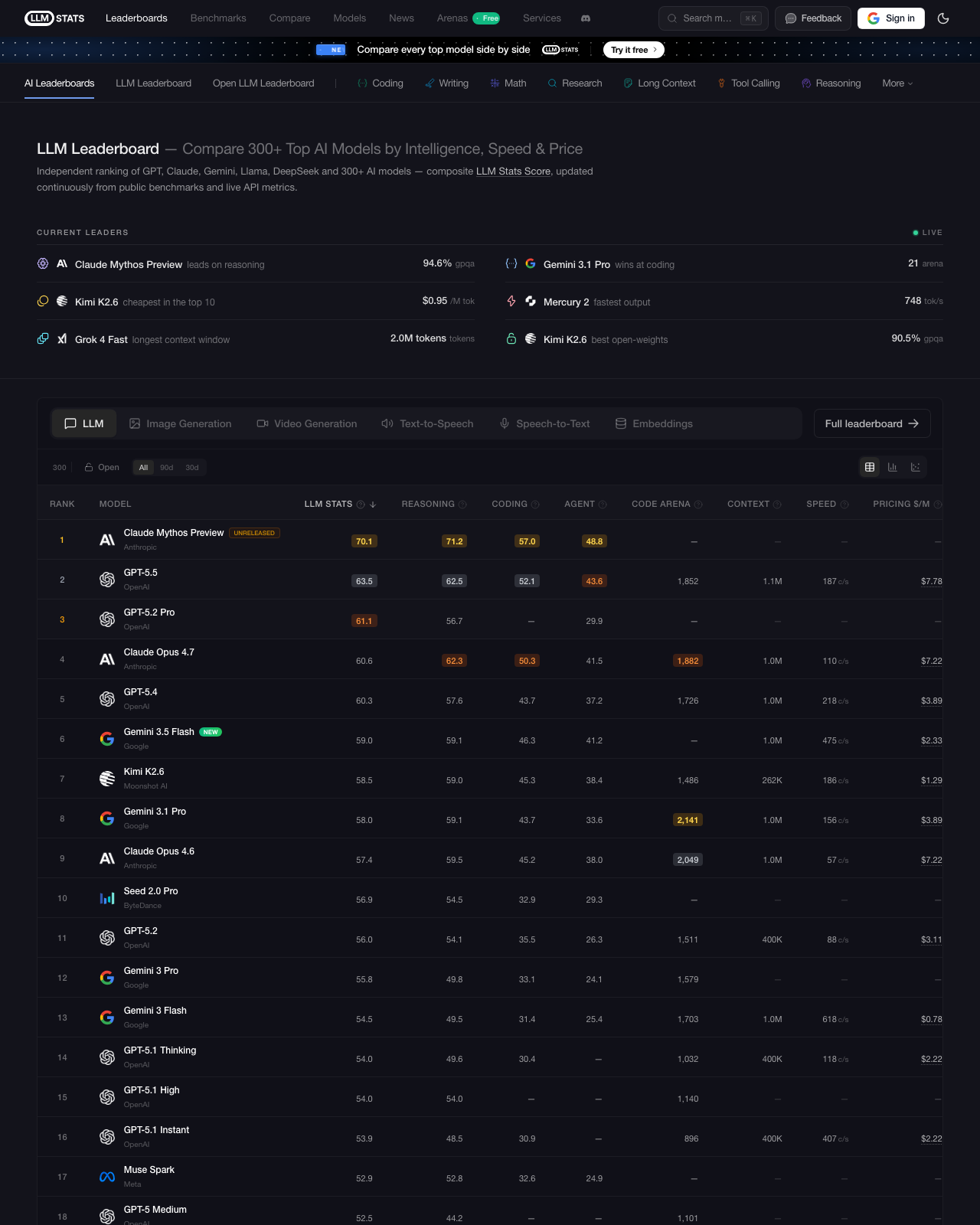 LLM Stats 全球 AI 模型排行榜。3.5 Flash 标记 NEW,空降第六。来源:llm-stats.com
LLM Stats 全球 AI 模型排行榜。3.5 Flash 标记 NEW,空降第六。来源:llm-stats.com
| # | 模型 | 综合 | 推理 | 编程 | Agent | 速度 | 价格/M |
|---|---|---|---|---|---|---|---|
| 1 | Claude Mythos Preview | 70.1 | 71.2 | 57.0 | 48.8 | — | — |
| 2 | GPT-5.5 | 63.5 | 62.5 | 52.1 | 43.6 | 187 t/s | $7.78 |
| 3 | GPT-5.2 Pro | 61.1 | 56.7 | — | 29.9 | — | — |
| 4 | Claude Opus 4.7 | 60.6 | 62.3 | 50.3 | 41.5 | 110 t/s | $7.22 |
| 5 | GPT-5.4 | 60.3 | 57.6 | 43.7 | 37.2 | 218 t/s | $3.89 |
| 6 | 🔥 Gemini 3.5 Flash | 59.0 | 59.1 | 46.3 | 41.2 | 475 t/s | $2.33 |
| 7 | Kimi K2.6 | 58.5 | 59.0 | 45.3 | 38.4 | 186 t/s | $1.29 |
| 8 | Gemini 3.1 Pro | 58.0 | 59.1 | 43.7 | 33.6 | 156 t/s | $3.89 |
盯着这张表看三秒钟,你会发现几个离谱的事情:
第一,速度碾压。 475 tok/s 是什么概念?表里所有模型最快的。GPT-5.5 只有 187,Claude Opus 4.7 只有 110。它一个打两个还有富余。
第二,价格屠夫。 $2.33/M 的综合价格,在前六名里是最便宜的。第二名 GPT-5.5 要 $7.78——3.3 倍的差价。同样的活,你用 GPT-5.5 花 100 块钱,用 3.5 Flash 只要 30。
第三,也是最让人倒吸一口凉气的——它把自己的"爸爸"干趴下了。 Gemini 3.5 Flash(59.0)综合分超过了 Gemini 3.1 Pro(58.0)。一个 Flash 级的"小弟”,在综合能力上反超了上一代旗舰 Pro。 这就像丰田出了一款卡罗拉,结果比去年的皇冠还快。
五、钱的问题:$1.50 到底值多少?
说太多数字容易麻,我们算几个真实场景:
场景 1:让 AI 通读你整个代码库
一个中型项目,50 万行代码:
- 输入:100 万 Token × $1.50 = $1.50(约 ¥11)
- 输出(假设 5 万 Token 的分析报告):$0.45(约 ¥3)
- 总计:不到 15 块钱。 一杯瑞幸的钱。
场景 2:用 Batch API 跑大批量任务
Google 提供了 Batch API,价格直接腰斩:
- 输入 $0.75/M,输出 $4.50/M
- 适合夜间挂机批量处理,成本又砍一半
场景 3:上下文缓存——反复读同一份文档
如果你的 Agent 需要反复翻阅同一份合同或代码库:
- 缓存读取只要 $0.15/M,是正常输入价的 一折
- 处理一份 100 页的法律合同,第二次以后每次只要几分钱
一句话总结:对于 API 调用者来说,3.5 Flash 把"用得起前沿模型"的门槛又往下踩了一大截。
六、API 开发者须知(快速版)
和现在所有主流模型一样,3.5 Flash 支持原生 Chain-of-Thought 推理,并提供了 thinking_level 参数控制推理深度(MINIMAL / LOW / MEDIUM / HIGH)——这跟 o1 以来的行业标准一致,没什么特别的。
但有两个小细节值得注意:
- Thinking Token 计入输出费用且占用
maxOutputTokens限额。 如果你发现回复被截断了,大概率是思考过程把输出配额吃掉了。解决方案:把maxOutputTokens调大。 - 多轮对话中有 Thought Signatures 机制。 模型会生成加密的推理状态签名,你需要在后续轮次中回传,否则推理会"断片"。
其他就不展开了,该有的文档 Google 都有:ai.google.dev/docs。
七、生态全景:不只是一个模型
3.5 Flash 不是单独放出来的,Google 正在下一盘更大的棋。
它现在在哪里都能用
| 平台 | 状态 |
|---|---|
| Gemini App(全平台) | ✅ 已设为默认模型 |
| Google 搜索 AI Mode | ✅ 已集成 |
| Google AI Studio | ✅ 可用(有免费额度) |
| Gemini API / Vertex AI | ✅ 生产可用 |
| GitHub Copilot | ✅ Pro/Business/Enterprise |
| Android Studio | ✅ |
Gemini Spark:AI 不睡觉,你可以
这次 I/O 最科幻的发布不是模型,是 Gemini Spark——一个 24/7 运行的个人 AI Agent。
它跑在 Google Cloud 的专属虚拟机上。你关掉电脑,它还在帮你干活:整理邮件、管日历、做调研报告。更刺激的是,Google 还搞了一个 Agent Payments Protocol (AP2)——你可以给 Agent 设一个消费预算,让它自己去订外卖、买软件许可证。
目前只对 Google AI Ultra 订阅用户开放 Beta。
下个月的大招:Gemini 3.5 Pro
Google 确认 3.5 Pro 正在内测,6 月份放出来。按 Google 的说法,这才是 3.5 世代真正的"旗舰"——如果 Flash 已经能空降排行榜第六,Pro 出来会是什么光景?
留个悬念。
八、灵魂拷问:所以我该换吗?
说了这么多,回到最实际的问题:对于不同角色的人,3.5 Flash 意味着什么?
如果你是开发者 / AI 工程师
值得立刻试。 理由很简单:
- 100 万 Token 上下文 = 整个代码库一次性塞进去,不用分片
- 475 tok/s = 你的 Agent 从"想半天再说"变成"脱口而出"
- MCP Atlas 83.6% = 工具调用开箱即用,目前最强之一
- $2.33/M 综合价格 = 跑 Agent 流水线不心疼
如果你是普通用户
打开 Gemini App,它已经默认切到 3.5 Flash 了。你能感知到的区别是:回复更快了。写文章、问问题、分析图片,体验会比之前更丝滑。
如果你是"等等党"
3.5 Pro 下个月就来了。但我个人建议不用等——Flash 和 Pro 的定位不同,一个要速度,一个要极限智能。看你的场景。
九、最终判断
先泼一瓢冷水:
- 排行榜数据主要来自 Google 自报,Terminal-Bench、MCP Atlas 等成绩还没被充分独立验证(毕竟模型刚发布)
- LMArena 的 Elo 评分还没稳定,早期估算约 1504,但样本量不足,需要 1-2 周才能看到可靠数据
- 输出偏冗长(冗长度是行业平均的两倍),实际使用中需要适当调教
- $9.00 的输出价格略高于行业均价($8.00),大量生成场景下成本会累积
但泼完冷水之后,热水还是热的:
Gemini 3.5 Flash 的定位精准得可怕——它不想做最聪明的模型,它要做最能干的模型。 在"智能足够用"的前提下,把速度拉到碾压级,把价格压到地板价。
2026 年的 AI 竞争已经不是"谁更聪明"的问题。当排行榜前十的模型智能差距已经缩小到几个百分点之内,真正的胜负手变成了:谁更快、谁更便宜、谁更好用。
Gemini 3.5 Flash 的答案是:全都要。
数据来源:Google 官方(blog.google, ai.google.dev)、Artificial Analysis(artificialanalysis.ai)、LLM Stats(llm-stats.com)、9to5Google、Mashable、VentureBeat、The New Stack。所有数据截至 2026 年 5 月 19 日。