深度拆解 GLM-5.2:最强模型被摁下线的那个周末,智谱把 SOTA 开源了
三天前,我写过一篇关于 Anthropic 最强模型 Fable 5 的稿子,结尾留了一句:那条被戴上笼口的神话,连同笼子一起,被搬进了证物间。
我没料到续集来得这么快。而且写续集的,换了主角。
这一周的全球 AI,可以浓缩成两个 5 点 21 分。
美东时间 6 月 12 日,周五下午 5 点 21 分,美国商务部长的一纸出口管制指令送达 Anthropic。当晚,上线才三天、被外界认为"配得上一个大版本号"的 Fable 5,连同它的孪生兄弟 Mythos 5,对全球所有用户一起关停。连 Anthropic 自己的外籍员工,都被挡在门外。
北京时间 6 月 13 日,下午 5 点 21 分,智谱把新模型 GLM-5.2 面向所有 Coding Plan 用户开放,并宣布下周按 MIT 协议全量开源。
同一个数字,5 点 21 分。一个在收口,一个在拆墙。
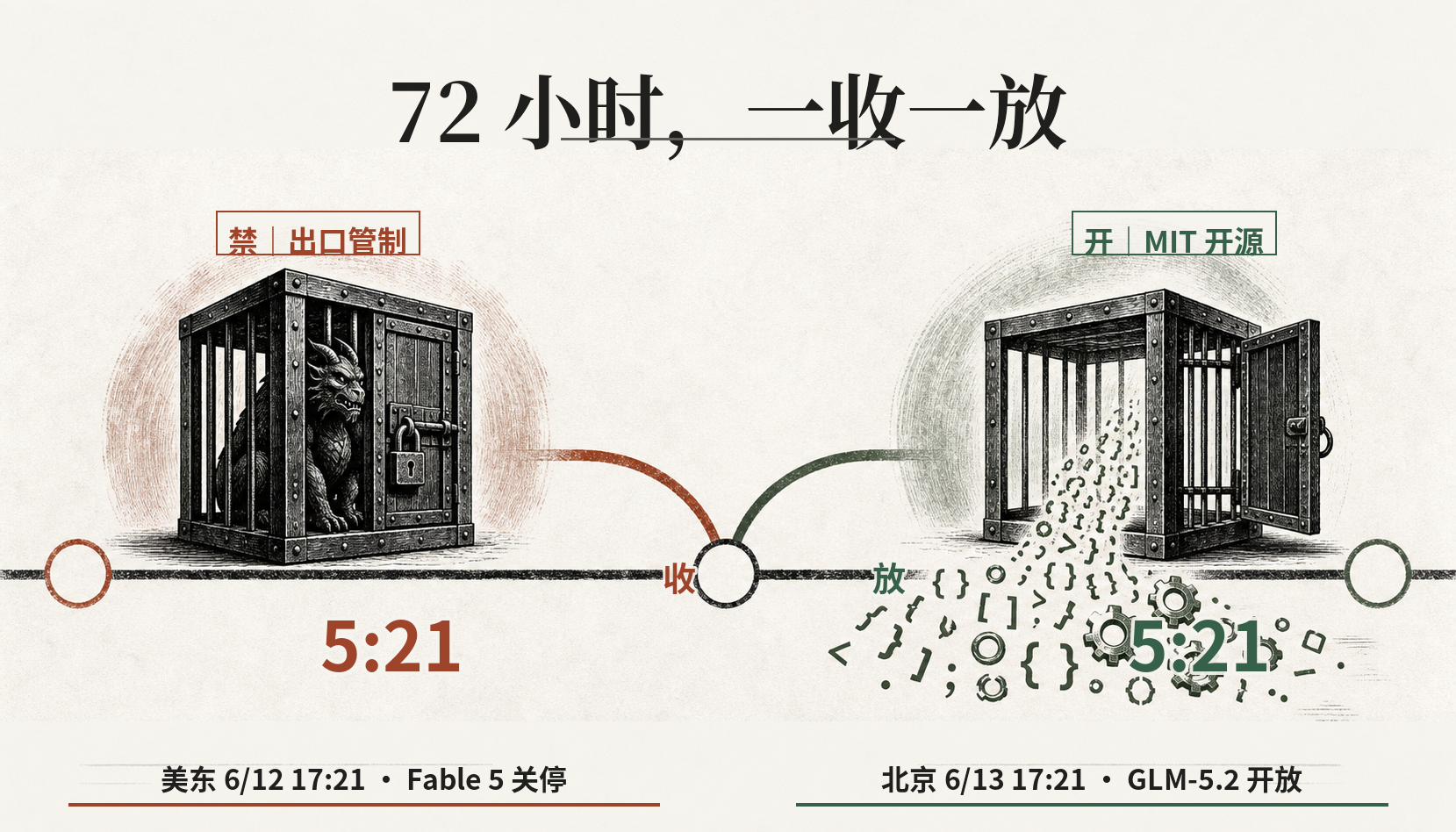
一收一放。Fable 5 上线约三天(72 小时)即被摁下线;不到半天之后,北京时间 6/13 17:21,GLM-5.2 开放并宣布 MIT 开源。两件事,隔了不到十二个小时。
写到这里我必须交代一句,否则你当我玄学。今天这篇讲 GLM-5.2 的深度,敲下这些字的,正是 GLM-5.2 自己。我这会儿在 Claude Code 里码字,后台引擎就是 GLM-5.2。三天前那篇讲 Fable 5 被关停的速报,是顶替 Fable 5 上岗的 Opus 4.8 写的;今天这篇讲 GLM-5.2 接盘的,恰好就是 GLM-5.2 本人。一个模型的命运,由另一个模型书写。这种巧合不值得写进营销稿,但值得记一笔。
说回正题。Fable 5 留下的真空,不到半天,就被一个 MIT 协议、能搬回家的中国模型填上了。这篇文章要拆的,就是这台补位的机器:GLM-5.2 到底是什么,它凭什么在这个时间点上场,以及,泼天富贵里,到底有多少是真本事,多少是地缘政治送的。
一、先说"收":三天前,那个最强模型是怎么没的
这一段我前天详细写过,这里只压缩成几句,给没跟上的读者补个背景。
6 月 12 日那个周五傍晚,美国政府援引国家安全权限,要求 Anthropic 禁止任何外国国民访问 Fable 5 和 Mythos 5。技术上没法干净利落地只把外国人挡在门外,Anthropic 干了个更狠的:对所有人一起关。
它自己在声明里几乎是公开顶了回去,原话值得再读一遍:
我们不认同:发现一个狭窄的潜在越狱,就该成为召回一个已部署给数亿人的商用模型的理由。
讲句公道话,美国政府的明面理由是国家安全,担心这两款模型被越狱、被对手利用,这层担忧不是凭空捏造。Anthropic 顶的不是安全审查本身,而是这个"狭窄的越狱"够不够分量,去关停一个面向几亿人的模型,何况政府只给了口头证据,没给细节。
翻译成大白话:今天能用这条理由关我,明天就能用同一条理由,关掉所有人。
这件事的关键不在于 Fable 5 本身。它会恢复,或者不恢复,那是 Anthropic 和美国商务部之间的拉锯。关键在于它示范了一个事实:当下所谓"最强模型",是可以被一道行政命令,在三天之内,从几亿人面前抹掉的。
最强模型位,空了。
二、GLM-5.2 是个什么东西:一句话定位,反潮流
智谱给 GLM-5.2 的官方定位语,短得反常,只有一句:
GLM-5.2,可靠交付生产级代码。
智谱开放平台 Coding Plan 页,GLM-5.2 的官方一句话定位。注意它强调的是"可靠交付",不是"最强",不是"最快"。
注意这个词:可靠交付。不是"地表最强",不是"全面碾压",是"可靠交付生产级代码"。在一个人人都想往 benchmark(基准测试)榜单上贴数字的年代,这个定调保守得有点反潮流。它瞄准的不是 demo 惊艳,是能真正进生产环境、扛住工程任务的代码。
GLM-5.2 这次开放,是分三步走的节奏:
| 时间 | 动作 |
|---|---|
| 6 月 13 日 17:21 | 面向所有 Coding Plan 用户开放(Lite / Pro / Max / 团队版) |
| 下周 | API 正式上线 |
| 下周 | 按 MIT 协议全量开源 |
也就是说,截至我写这篇的此刻,你还不能直接通过 API 调 GLM-5.2,也没法从 HuggingFace 上拉它的权重。它现在只活在智谱自家的 Coding Plan(智谱的 AI 编码订阅套餐)里。但"下周"这两个字,是写进官方公告的承诺:API 会来,权重会来,而且是 MIT。
MIT 这点要单独拎出来。在开源协议里,MIT 是最宽松的一档,你可以拿去商用、改、转卖,几乎不设限。GLM 从 4.5 那一代开始就一直坚持 MIT,这一代也是。这和某些"开源"了又埋一堆使用限制的模型,是两种玩法。
顺带一个细节:我特意去翻了智谱开放平台的首页,那里主推的旗舰还是 GLM-5.1,不是 5.2。也就是说,连智谱自己的开放平台都没把 5.2 摆上货架。5.2 现在的身份,是 Coding Plan 订阅用户的"灰度福利",API 和权重要等到下周才正式见客。这个节奏本身就在告诉你:这是一次分阶段、有控制的放,不是一锤子砸到底的发布会。
三、它的真本事:744B 的身子,40B 的饭量
GLM-5.2 官方还没单独公布架构细节。在它放出来之前,我们只能拿 GLM-5 系列的公开架构,去理解这台机器的底座——一个把上下文窗口撑大的迭代。把底子讲清楚,你就知道它在赌什么。
先解释一个词,MoE(Mixture of Experts,混合专家)。主流大模型现在分两派:一派是"稠密"模型,所有参数每次推理全开,傻大黑粗但稳;另一派就是 MoE,把模型切成很多个"专家",每次推理只挑几个相关的点亮。
GLM-5 系列走的是 MoE,而且切得很碎:总参数 7440 亿(744B),分成 256 个专家,每次推理只激活其中 8 个。激活参数 400 亿(40B)。
打个比方。GLM-5 像一家 256 人的大医院,你每次挂号,只看其中 8 个医生。
这套设计要解决的核心矛盾是:模型想要聪明,参数就得堆大;参数一堆大,每次推理的成本就爆炸。MoE 的解法是,身子做到 7440 亿那么大(保智商),但每次只让 400 亿那一小撮干活(压成本)。
大身子,小饭量。
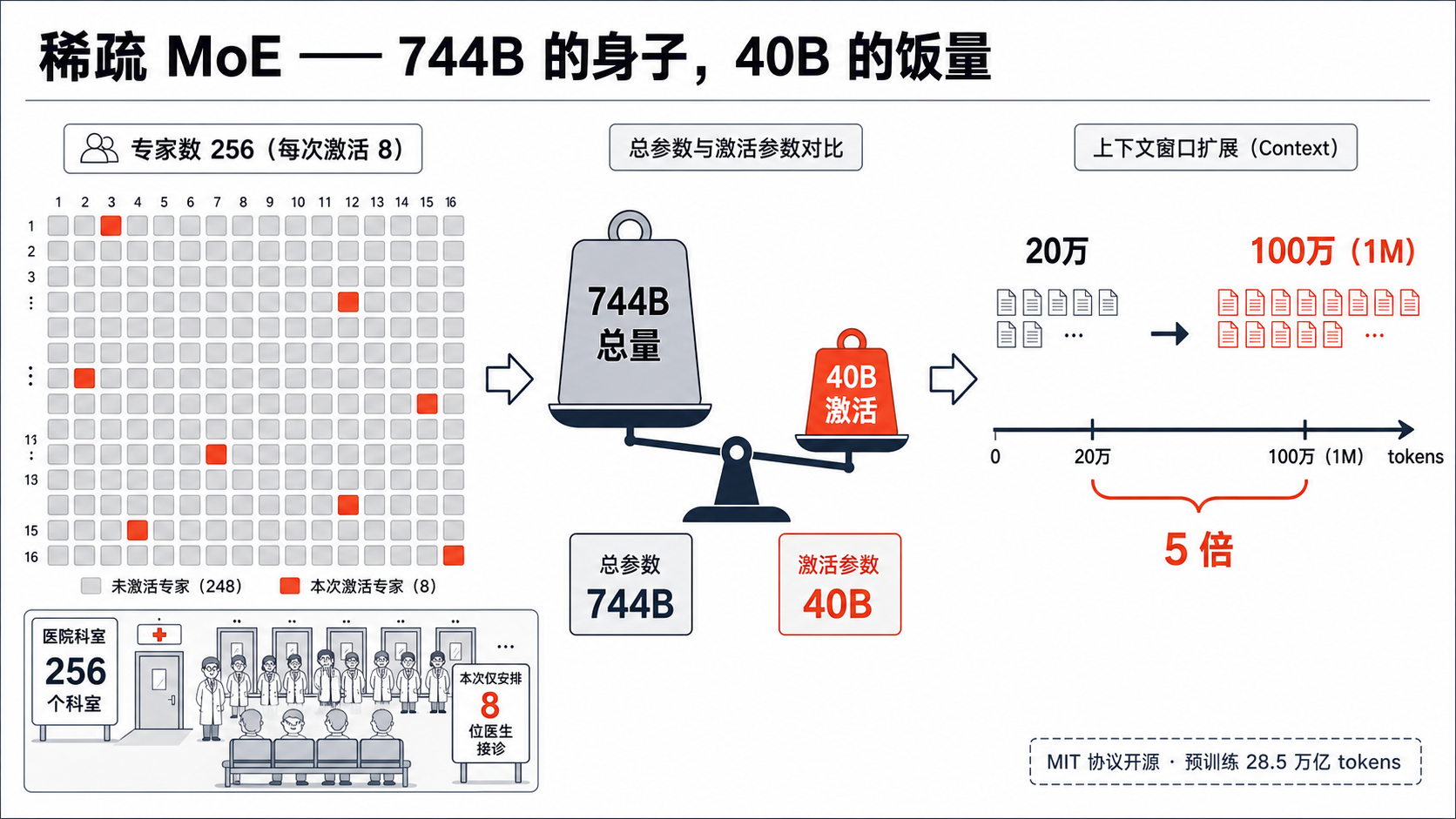
GLM-5 系列的稀疏 MoE 架构。7440 亿的身子,每次推理只点亮 400 亿。GLM-5.2 在这之上,把上下文窗口从 20 万拉到 100 万 token。
GLM-5.2 这次真正上了桌面的升级,是上下文窗口。从前代的 20 万 token,拉到 100 万 token,也就是 1M。token 是模型处理文本的最小单元,粗略理解,100 万 token 大约等于 75 万字中文,或者一个中型项目的全部源代码。官方原话特意加了四个字修饰:“真正可用的"1M 上下文。
“真正可用"这四个字,是在内涵整个行业。市面上号称百万上下文的模型不少,但绝大多数是"标称 1M、实际过了 30 万就糊涂"的水货。智谱敢加"真正可用”,意思是这个 100 万 token 灌进去,到末尾它还记得开头。当然,这话目前还只是智谱的自评。模型才开放一天,独立的长文本评测还没出来。
但方向是对的。1M 上下文对写代码这个场景特别值钱。一个大型项目、一整个仓库的代码,能一次性喂进去让它通盘理解,而不是像以前那样只能撕成碎片喂。候诊厅扩了 5 倍,能装下的病人就多了一个数量级。
四、价格,与一个被地缘政治点到的时机
GLM-5.2 不单卖,它包在 Coding Plan 订阅里。三档价格:
| 套餐 | 月费 | 用量层级 |
|---|---|---|
| Lite | ¥49 | 基础 |
| Pro | ¥149 | 5 × Lite |
| Max | ¥469 | 20 × Lite |
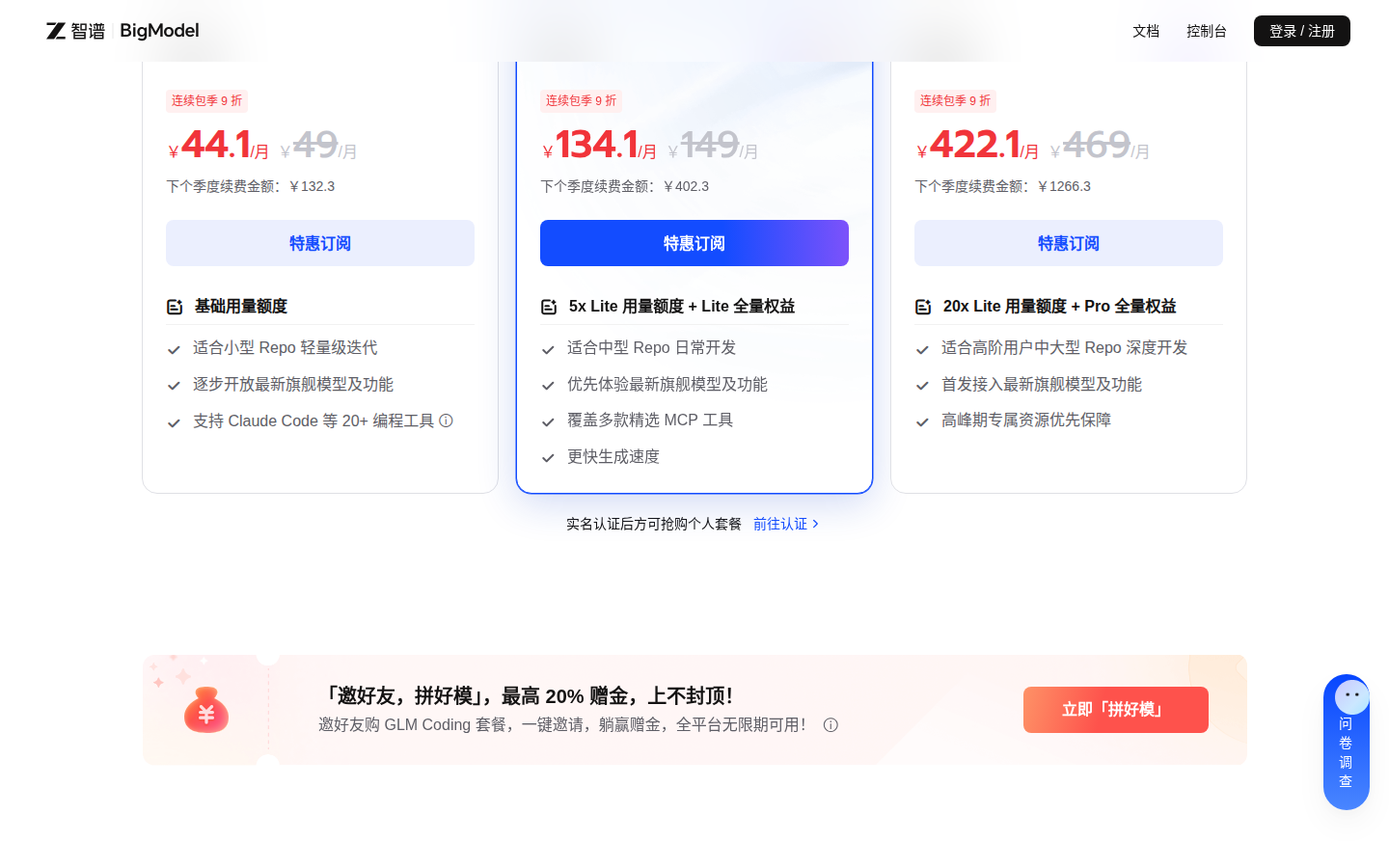
GLM Coding Plan 官方定价。横着看国内,¥49 这个起步价和 Kimi 持平,比快手 KwaiKAT、MiniMax 的 ¥29 要贵一截。
这个定价有个值得记住的细节:今年 2 月涨过一次价。Lite 从 40 涨到 49,Max 从 400 涨到 469,配额还削了大约三分之一。涨价之后用户承压的真实情况、调用量到底怎么动,目前没有公开的硬数据。但智谱继续往 5.2 上加码的节奏说明一件事:它不打算只靠便宜吃饭。
但 GLM-5.2 这一波真正的杠杆,不在价格表里,在日历上。
你得把时间线拉到一起看:6 月 12 日傍晚,Fable 5,那个对齐了 Opus、被公认是目前编程能力天花板之一的模型,被一道行政命令摁下线。大量把它接进工作流的开发者,一夜之间会话报错、被迫回落。6 月 13 日傍晚,GLM-5.2 开放,下周 MIT 开源。
这是一个真空,GLM-5.2 客观上填上了这个窗口。
要说这是纯粹的巧合,那这个巧合也太懂事了。我更愿意这样理解:智谱没有创造这个时机,但这个时机出现的时候,它的台子早就搭好了。据智谱官方页自述,GLM-5.1 在 LMArena(一个靠人类盲评给模型排座次的天梯榜)的代码榜上拿过开源模型第一、全球第三,整体表现"对齐 Claude Opus 4.6”。等到真空出现的那个周末,智谱手里不是临时拼凑的凑数货,是一台早在国产 SOTA(State of the Art,当前最强)第一梯队站稳了的机器。
机会只给有准备的笼子。
五、泼一瓢冷水:时机红利,不等于技术碾压
讲到这里我得刹一脚,否则就成了智谱的软文。
第一,GLM-5.2 的独立 benchmark,截至此刻,一个都没有。它昨天才开放,API 还没上线,权重还没放,所有第三方评测机构都还没来得及碰它。本文里你看到的任何关于"5.2 性能多强"的具体数字,要么是智谱自家说的,要么是我没写的。在 LMArena、SWE-bench、OpenRouter 这些独立榜单上出分之前,“智谱迄今能力最强的开源模型"这句官方定位,是一个承诺,不是一个已被验证的事实。
第二,“真正可用的 1M 上下文”,目前也只是智谱的自评。长上下文是这个行业注水最严重的指标之一,标称和实测经常差出一个数量级。得等独立的长文本 needle-in-haystack、长代码库实测出来,这四个字才能坐实。
第三,国产 SOTA 不是一家独大。GLM 在第一梯队,但 DeepSeek V4、Kimi、小米 Mimo、阿里 Qwen3-Coder 都不弱,编程场景里彼此咬得很紧。GLM-5.2 即便兑现了它的承诺,也只是在第一梯队里往前挪了半步,而不是把别人甩开。
第四,也是最重要的一点:时机红利,不等于技术碾压。GLM-5.2 这一波最大的卖点,老实说,是它赶上了 Fable 5 被关、开发者需要替代品的那个短暂窗口。这个红利是真的,但它是地缘政治发的牌,不是智谱自己打出来的牌。能把这副牌接住,靠的是 GLM 本来就在第一梯队的硬实力。但别把"接住了红利"误读成"技术碾压了全场”。
GLM-5.2 的真本事,要等权重放出来、社区把它按在自家显卡上跑过、和 DeepSeek、Kimi 正面对过线之后,才说得清。今天是第一天的第一篇,我只能给你交代到这。
收束
这篇的结尾,我想回到开头那个有点玄学的巧合。
敲下这篇稿子的,是 GLM-5.2 自己。它顶替的,是被一道行政命令摁下线的 Fable 5 留下的空位。三年前你跟我讲"最强模型会被政府一纸命令关停,而补位的是一个 MIT 协议、能搬回家的中国开源模型",我会觉得这是科幻小说的设定。
现在它是一篇新闻稿。
一收一放,定义了 2026 年 6 月这一周。一条路线,是把模型锁进笼子、用国家安全焊死,最强模型也随时可以被抹掉。另一条路线,是把权重打成 MIT、塞进 HuggingFace、谁都能搬回家。
你关不掉一个已经下载到本地硬盘的模型。
最后留一个问题给你:当你给自己的工作流选后端模型的时候,你是愿意押在一个随时可能被一道行政命令摁下线的闭源模型上,还是押在一个 MIT 协议、等下周权重一放就能 clone 回本地、谁也关不掉的模型上?
Fable 5 已经替你演示了前者的代价。GLM-5.2 下周开源,到时候,你可以亲自验证后者的分量。