Claude Code 动态工作流:几百个 AI 同时干活,怎么才不乱套?
先想象一个场景。
你手里有个老项目,五百个代码文件,你想让 AI 帮你挨个查一遍,看有没有安全漏洞。
一个 AI 干这活,不现实,文件太多,它看到后面就忘了前面。很自然地,你会想:那能不能一口气开几十个 AI 分身,一人分几十个文件,一起查?
听上去就很快。但真做起来,第一个拦路的问题不是 AI 聪不聪明,而是——
这几十个分身,谁来指挥?
谁分配谁查哪些文件,谁来盯进度,谁来汇总结果,查出可疑的地方谁去复核。这套"调度"的活,一直是 AI 多分身协作里最别扭的一环。Claude Code 五月底上线的动态工作流(Dynamic Workflows),整件事就是冲着这个最别扭的环节去的。
这篇我想把它讲明白:它到底解决了什么,凭什么解决,以及里面藏着的两条挺聪明的工程智慧。
老办法的天花板:指挥全靠一个大脑硬记
先说说"以前"是怎么干的,你才知道新东西新在哪。
以前那个"总指挥",就是 AI 自己。你给它派个大活,它一边想一边往外派分身,分身干完,把结果一股脑塞回它那里。问题就出在这个"塞回它那里"。
AI 干活时有个东西叫上下文窗口,你可以把它理解成 AI 的工作台,或者一张随身的记事本,就是它当下能记住、能摊开看的所有东西,就这么大一块。所有分身的结果往这上面堆,很快就堆满了。
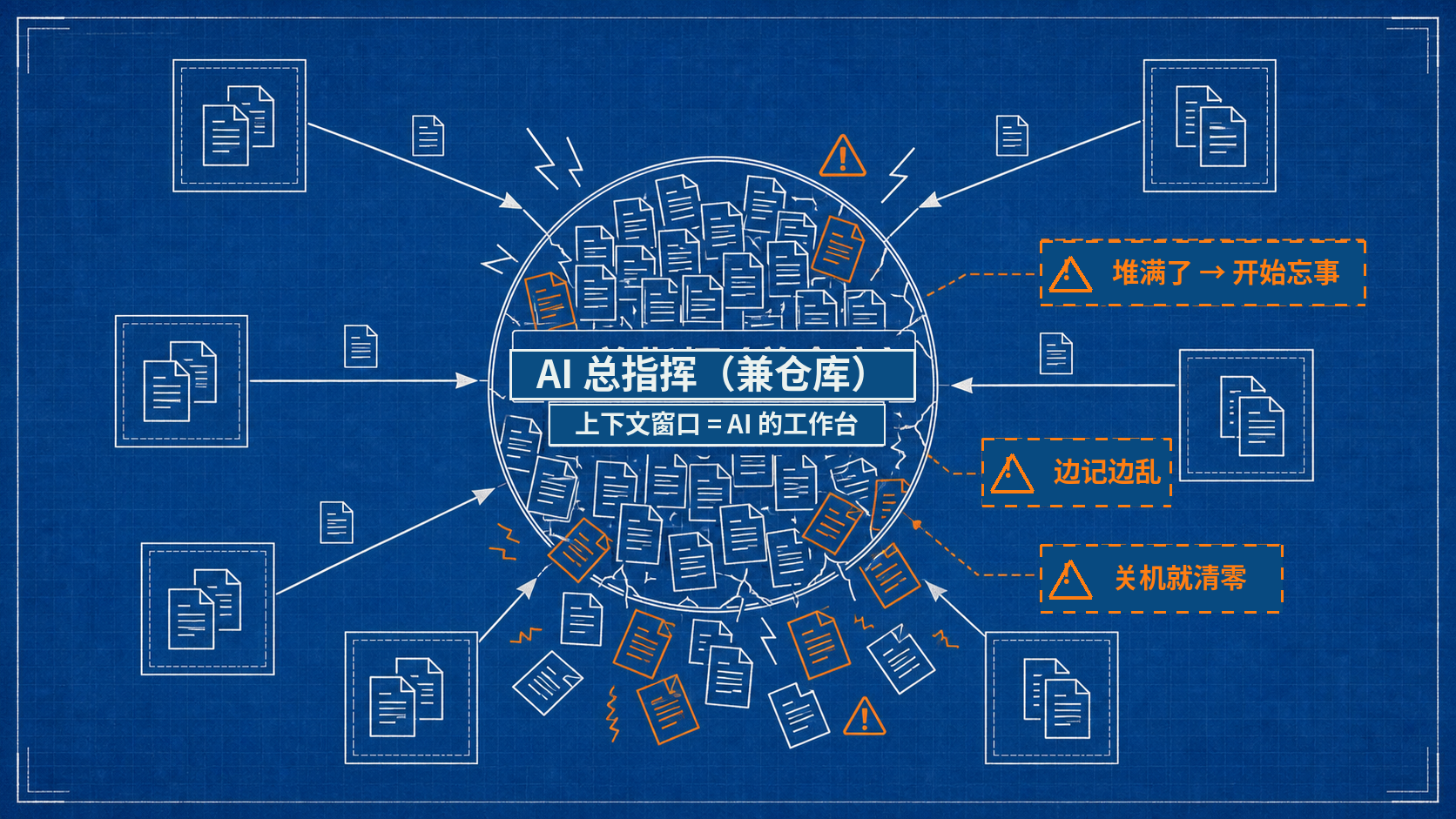
一个 AI 既当指挥又当仓库,几十个分身的结果全堆回它的"工作台",台子很快堆爆。
堆满之后,麻烦是连环的。
桌子就那么大,堆不下,前面的细节开始往外掉,它就开始忘事。边记边派、边派边忘,时间一长它自己都乱了,今天这活到底怎么分的、谁先谁后,你让它复述,它说不清。最要命的是,这一摊全在它脑子里,它这轮对话一结束,整套打法就跟着蒸发了——明天你想原样再跑一遍,对不起,从头再教一遍。
这不是 AI 不够强,是"组织协调"这件事,卡在了一个"全靠一个大脑硬记"的笨地方。这就是那段最难走的"最后一公里"。
新办法:把"怎么干"写成一张图纸
动态工作流的解法,说穿了一句话:别让总指挥拿脑子硬记了,先让它画一张图纸。
你描述任务,AI 不再自己一轮一轮地现场派活,而是先写出一份计划:哪些活同时开干、哪些活得排队等、干完怎么验收、什么情况下收工,全写成明明白白的步骤。这份计划是一段代码,但你不用懂代码,你只要知道:它是一张钉在墙上、谁都能照着执行的施工图纸。
图纸画好,交给一个在后台待命的"调度台"照着跑。这下关键的变化来了。
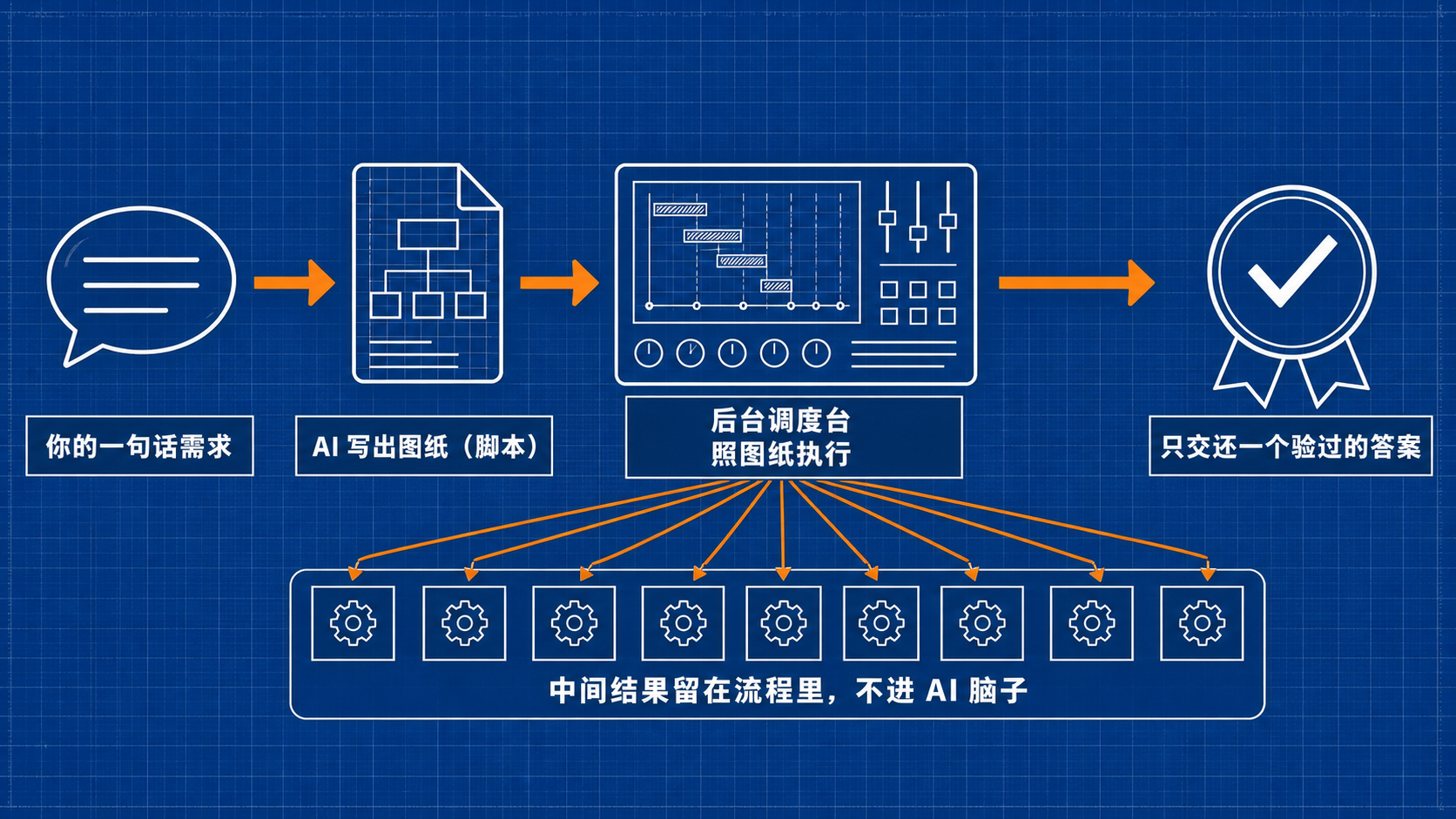
你一句话 → AI 写出图纸 → 后台调度台照图纸开几十上百个分身 → 中间结果都在图纸的流程里流转 → 最后只把一个验过的答案交还给你。
那几十上百个分身的中间结果,从此待在图纸的流程里流转,不再往 AI 的脑子里灌。AI 的工作台,从头到尾只接最后那一个答案。
脑子不爆了,因为脑子不再是仓库。
它能干多大的活?官方摆出来的样板有点吓人:有人用它把整个 Bun(一个挺大的开源项目)从 Zig 语言重写成了 Rust。七十五万行代码,相当于把一本几千页的天书逐字翻译成另一种语言,还要保证功能一字不差,最后已有测试的通过率 99.8%,从动手到合并,十一天。数百个分身同时在写,每个文件还另外配两个分身专门挑错。Anthropic 自己的原话是:过去得按季度排期的活,现在几天干完。
第一条智慧:别让快的,干等慢的
光是"能开几百个分身"并不稀奇。图纸里真正值钱的,是它逼着你把"活该怎么排"想清楚。这里有个反直觉的坑,我用前面那个查文件的例子讲,你一看就懂。
假设每个文件要走两步:先"通读一遍、圈出可疑的地方",再"挨个核实、确认是不是真漏洞"。
笨办法是这样:先派一批分身,把所有文件都通读一遍;等全部读完了,再统一开始核实。听着挺顺,对吧?但坑就在这儿:文件有长有短,长的读得慢。先读完的那些分身,活儿干完了却不能往下走,只能干坐着,等那个最慢的文件也读完,大家才一起进入"核实"。一堆人在空等。
聪明办法是另一套:哪个文件先读完,立刻就送去核实,绝不等别人。这边在核实第一个文件,那边第二个文件还在通读,错峰流动,谁也不耽误谁。
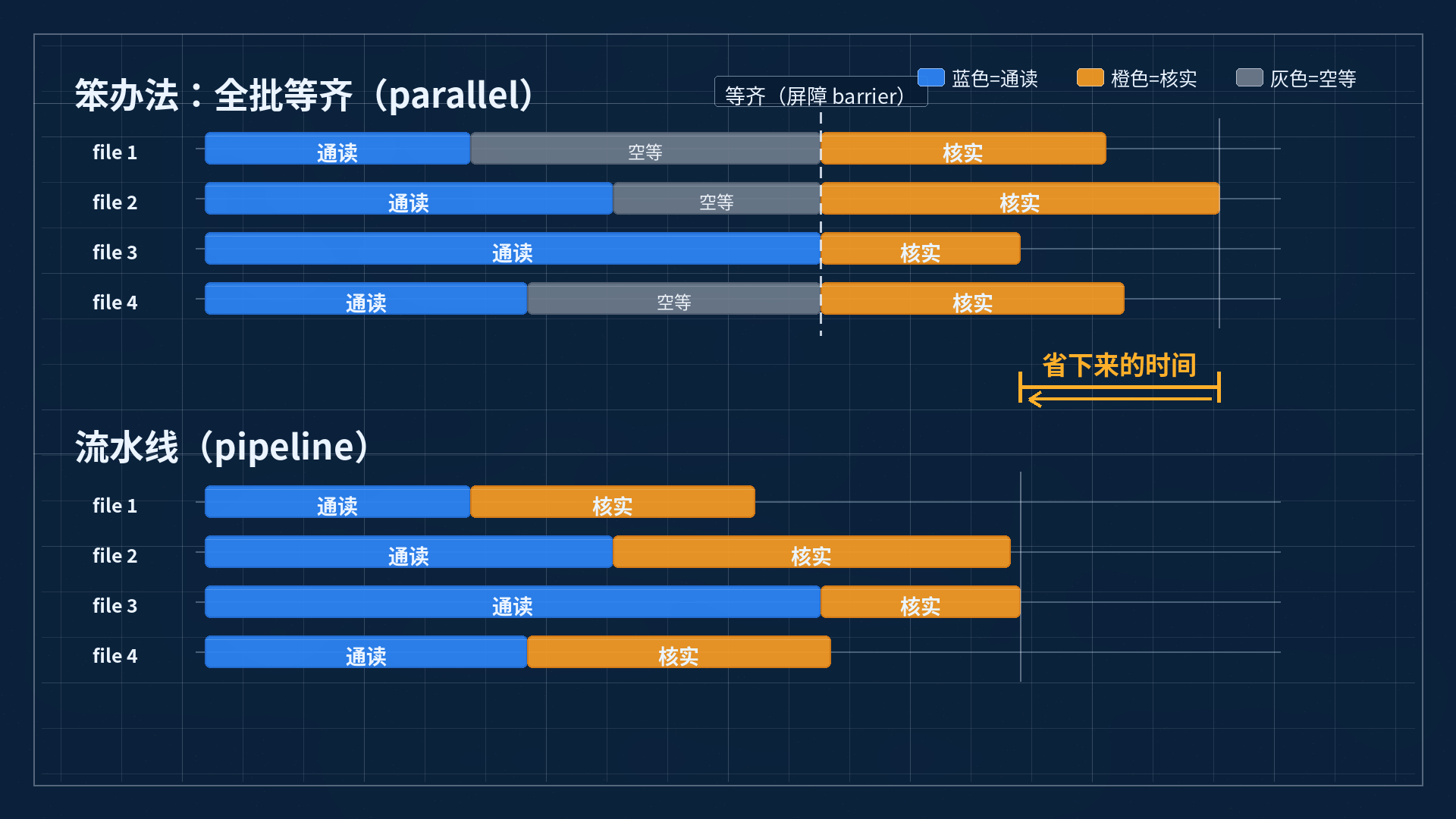
上半截是笨办法:全部读完才一起进核实,先干完的在"空等"(灰色),总时间被最慢的那个拖长。下半截是流水线:读完一个立刻核一个,错峰流动,整条线明显更短。
这两套办法,在动态工作流里有名有姓。笨办法那种"全批等齐再走"的,叫 parallel(),中间那道"等齐"的关卡,行话叫屏障(barrier)。流水线那种"读完一个走一个"的,叫 pipeline()。
官方把 pipeline() 定成默认首选,parallel() 只在一种情况下才用:下一步真的必须凑齐上一步的全部结果(比如要把所有文件的问题汇总去重之后,才能往下)。除此之外,能流水线就别等齐。
这一刀,正好切在多分身协作最爱白白浪费时间的地方。
第二条智慧:不让任何一个分身说了算
分身一多,还有个新麻烦:人多,错也多。某个分身信誓旦旦报上来"这里有个大漏洞",听着挺像回事,可万一是它看走眼了呢?
动态工作流的应对很有意思:一条结论冒出来,它不直接信,而是再派几个分身,任务不是复核,是专门来推翻它。默认你是错的,谁也别想一句话定案,扛得住围攻的才作数。
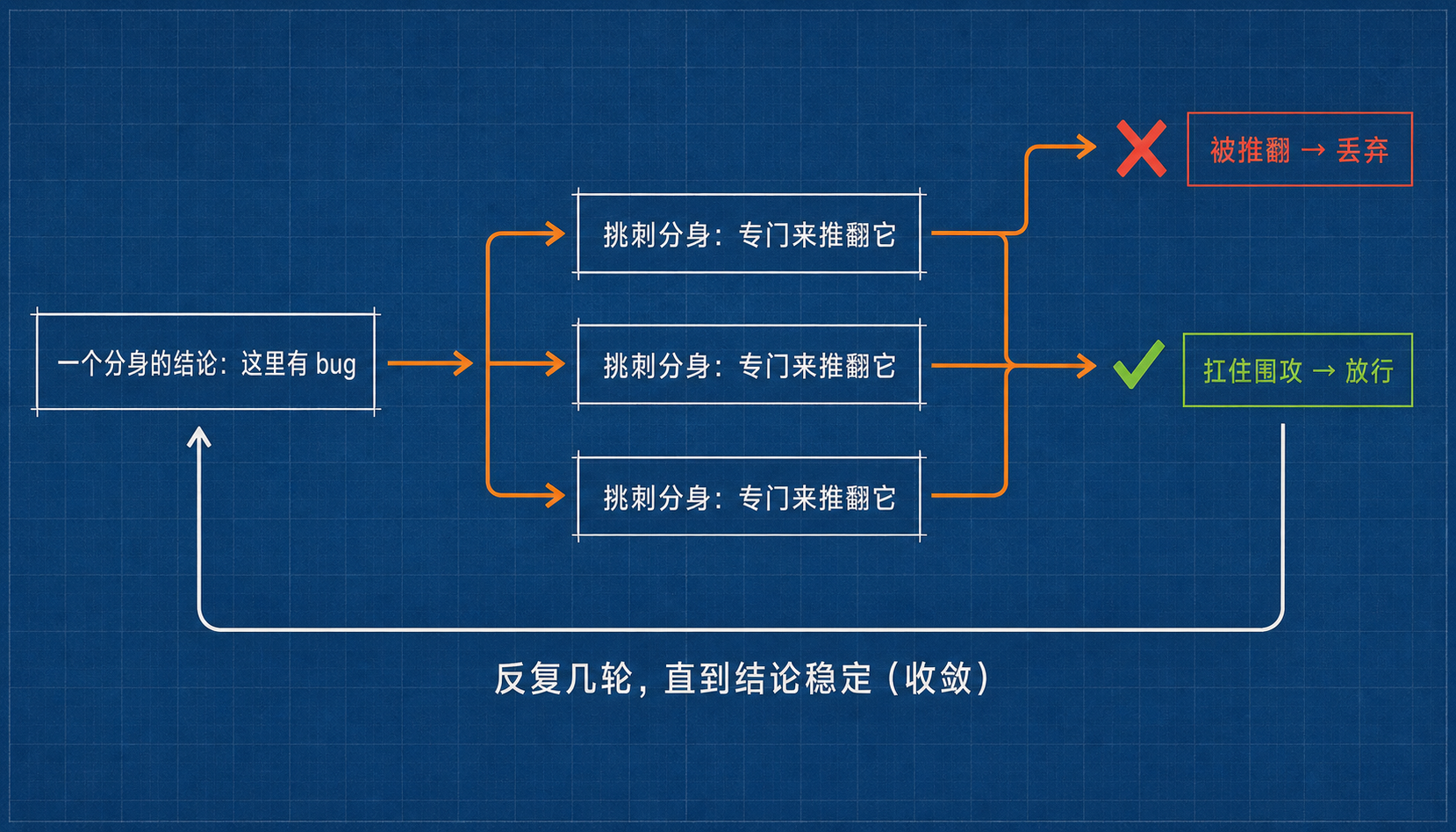
一个分身给出结论,几个"挑刺"分身专门来证伪;推翻了就当场丢弃,扛住了才放行。反复几轮,直到大家吵不出新东西、结论稳定下来。
Claude Code 自带的 /deep-research(深度调研)就是这么跑的:每条结论都要过一轮交叉投票,扛不住核验的当场删掉,根本进不了最终报告。你拿到手的,是已经被自己人挑过刺的版本。
这里有句话得说清楚:稳定的是这套流程,不是每个分身。照着图纸干活的每个分身,本质还是个会看走眼的 AI。它聪明就聪明在没装:没假装分身不犯错,而是干脆把"互相验"做成了流程本身的一环。先承认会错,再用结构去兜,比嘴上拍胸脯靠谱得多。
泼盆冷水
别急着上头,几句实在话。
它现在是研究预览(research preview),不是稳定功能,得 Claude Code v2.1.154 以上的版本才有。能同时开的分身上限 16 个,单次任务总共封顶 1000 个,不是无限。
更现实的是钱。几百个分身同时干活,等于几百张嘴同时吃你的算力账单(token)。“按季度的活几天干完"的另一面,是账单也烧得飞快。官方自己都把这句写在了显眼处:动态工作流烧的 token,比一次普通对话多得多。所以官方给的建议特别朴实:先拿一个目录、一个小问题试着跑,盯着进度面板上实时跳的数字,心里有底了,再放开手干全量。
还有一层得拎清楚:图纸是确定的,能稳定复现;但照图纸干活的,还是一群会犯错的 AI。“稳定"指的是这套编排流程可靠,不等于"每个分身的结论都对”。把这两件事混为一谈,迟早摔跤。
真正变的是什么
绕回开头那个问题:几百个 AI 一起干活,谁来指挥?
过去的答案是 AI 自己拿脑子硬扛,扛到忘、扛到乱、一关机就清零。现在的答案是:先写一张图纸,让图纸去指挥。
所以这次真正变的,不是 Claude 能一口气开几百个分身,分身这事早就有了。变的是,“怎么干"这件事,第一次从一次性的灵光一现,落成了一张你能读、能改、能存档、明天能照着原样再跑一遍的图纸。跑顺了,存成自己的一道命令,下回一句话就调出来。
编排,从一种当场发挥的本事,变成了一种攒得下来的资产。
那么下一个问题就来了:当"怎么干"变成了可以版本管理、可以传给同事的代码,一个团队真正的护城河,可能就不再是"谁家的 AI 更聪明”,而是——谁攒下了那张更好的图纸。