深度拆解 MiniMax M3:一台水桶机,亲手锯掉了自己唯一的长板
如果把这两年的国产大模型摆成一条美食街,MiniMax 一直开的是那家沙县小吃。
不是说它差。是说它定位极其清晰:不主打好吃,主打便宜、量大、管饱,开遍全国每个街角。去年那款 M2,靠着"性能 T1 中游、价格只有 Opus 零头"的打法,成了开源圈一阵旋风——官方那条推文的标题就叫"Mini Price, Max Performance",迷你的价格,最大的性能。在一个 Opus、GPT、Gemini 神仙打架、动辄几十刀输出价的市场里,MiniMax 把自己的护城河挖在了一个谁都懒得跟它抢的地方:便宜。
今天,2026 年 6 月 1 日,沙县小吃发布了自己的米其林宣言。
M3 一口气端出三道招牌菜:100 万 token 的超长上下文、从第一步就原生训练的多模态、对标 Opus 和 GPT-5.5 的前沿编程能力——而且是目前唯一把这三样塞进同一个开放权重模型的玩家(权重和技术报告,官方说 10 天内放出)。摆盘对标人均千元的法餐,气势很足。
问题出在两个地方。一是菜端上来,实测是预制菜水准;二是结账时我看了眼账单——它按米其林收。
这篇我们就掰开揉碎,看这台"什么都想要"的水桶机,到底端出了什么,又悄悄拿走了什么。
一、先把三道招牌菜摆上桌
M3 的卖点是"三合一",我们一道一道看,顺便把里面的黑话翻译清楚。
第一道:100 万 token 上下文,靠一个新注意力机制撑起来。
上下文窗口你可以理解成模型的"工作记忆"——一次能塞进多少字让它同时看着。1M token 大概是一整个中型代码仓库、或者几百页文档的量级。难点在于,传统注意力机制(full attention)的计算量是随长度平方增长的:长度翻一倍,算力翻四倍。撑到 1M,成本会爆炸。
MiniMax 的解法是自研的一套稀疏注意力,名字叫 MSA(MiniMax Sparse Attention)。稀疏注意力的思路,是不让模型在每个字上都把前文从头扫一遍,而是先做一道"预筛选",只精算那些真正相关的片段。MSA 的工程取巧在于一个叫"KV outer gather Q"的算子设计——每个数据块只读一次、内存访问连续,按官方的说法,比开源界现成的 Flash-Sparse-Attention 快 4 倍以上。
落到结果上:在 1M 上下文长度下,M3 每个 token 的计算量只有上一代的 1/20,预填充阶段提速 9 倍以上、解码阶段提速 15 倍以上。这是 M3 这次最硬、也最没水分的一块——架构层面的真创新,不是调参堆出来的。
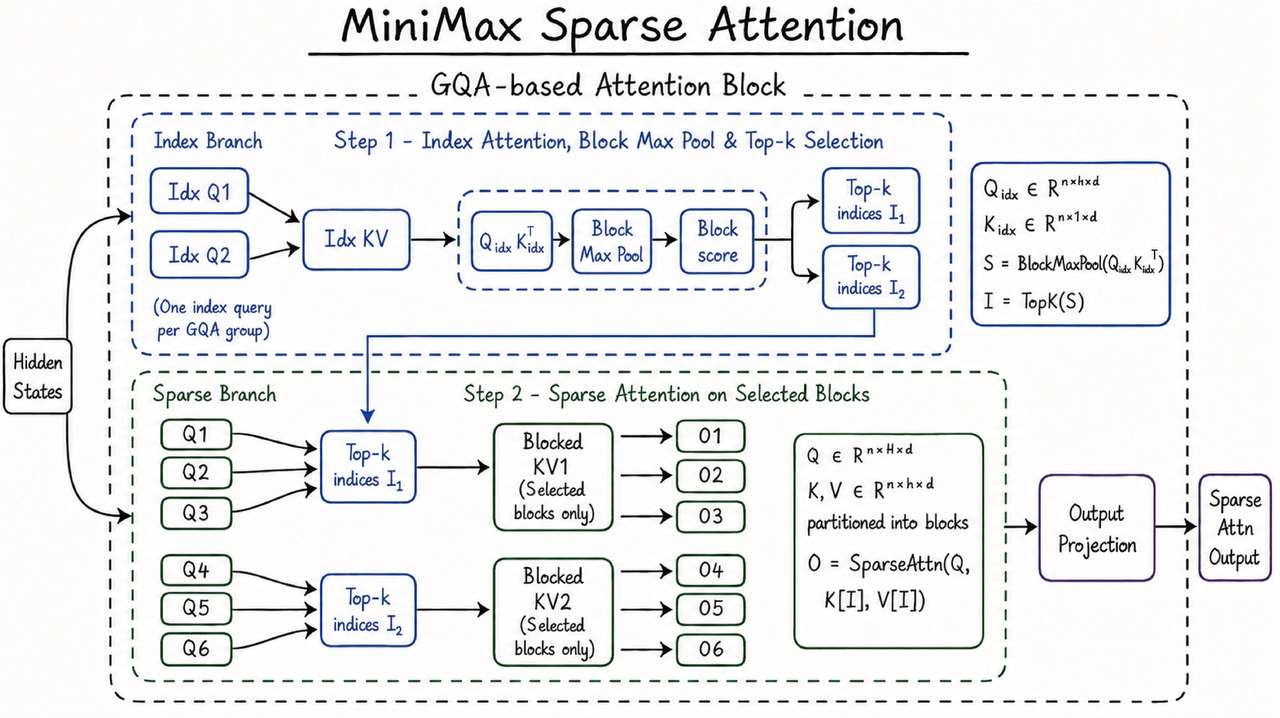
MiniMax 官方给出的 MSA 结构图:先用 GQA 做块级索引和 Top-k 选择(Step 1),再只在选中的块上算稀疏注意力(Step 2)。来源:minimax.io/blog/minimax-m3
第二道:原生多模态,从第 0 步就混着练。
“原生多模态"这个词要解释一下,因为它和"后接一个视觉模块"是两回事。很多模型是先把语言练好,再缝一个看图的接口上去,图文是两套语义、勉强对齐。M3 走的是另一条路:从预训练的第 0 步开始就把文字、图像、视频混在一起喂,让不同模态的语义空间从底层就长在一起。官方为此重建了整条数据管线,把训练数据规模拉到了 100T token 这个量级。
能力上,M3 支持图片和视频输入,甚至能直接操作电脑桌面——这一条后面讲它的 Agent 工具时会用到。
第三道:前沿编程与 Agent 能力。
这是 MiniMax 这次最想让你记住的卖点。官方海报上,M3 在一串编程评测里数字都很漂亮:
| 评测 | M3 成绩 | 官方说法 |
|---|---|---|
| SWE-Bench Pro | 59.0% | 超过 GPT-5.5 和 Gemini 3.1 Pro,逼近 Opus 4.7 |
| Terminal-Bench 2.1 | 66.0% | —— |
| SWE-fficiency | 34.8% | —— |
| KernelBench Hard | 28.8% | —— |
| MCP Atlas | 74.2% | —— |
| Claw-Eval | (最高分) | 自主 Agent 端到端评测拿了第一 |
数字单看都不错。但 benchmark 这东西,恰恰是最容易骗人的地方。我们下一章就拿全表来对一对。
二、官方海报的摆盘,和全表的真相
先说我评价一个模型的老规矩:不信单一榜单。客观 benchmark、LM Arena 的人类盲评、OpenRouter 上真金白银的消费者用量,三者交叉,没有明显偏离才算数。因为业界有大量 benchmark 在变相鼓励"高分低能”——在测试集上训练、或者专挑自己赢的那几个小众评测往海报上印,让你误以为它性价比很高。
M3 的官方海报,就是一份教科书级的"精选展示"。

MiniMax 官方发布图,精心挑了四个对手:M3 vs Opus 4.7 vs GPT-5.5 vs Gemini 3.1 Pro。来源:minimax.io/blog/minimax-m3
你盯着这张图看一会儿就会发现门道。它确实有赢的:SVG-Bench 上 M3 的 63.7 是四个里最高,MCP Atlas、BrowseComp、BankerToolBench 也咬得很紧。但官方放在通稿里吹的那个 Terminal-Bench 2.1 “66.0%"——你看图就明白了,GPT-5.5 是 78.2,Gemini 是 70.3,连 Opus 4.7 都有 66.1,M3 这个 66.0 是四个对手里垫底的,差着 0.1 没够到 Opus。GDPval 那一栏,M3 的 74.7 也被 Opus 的 79.8、GPT 的 80.6 压在底下。把一个垫底的数字挑出来当卖点,这就是摆盘的艺术。
真正诚实的一张图,是 MiniMax 自己也放了、但你得往下翻才看得到的全量对比表。我把它拉出来——这次连开源同行 DeepSeek V4 Pro、GLM 5.1、Kimi K2.6 一起摆上:
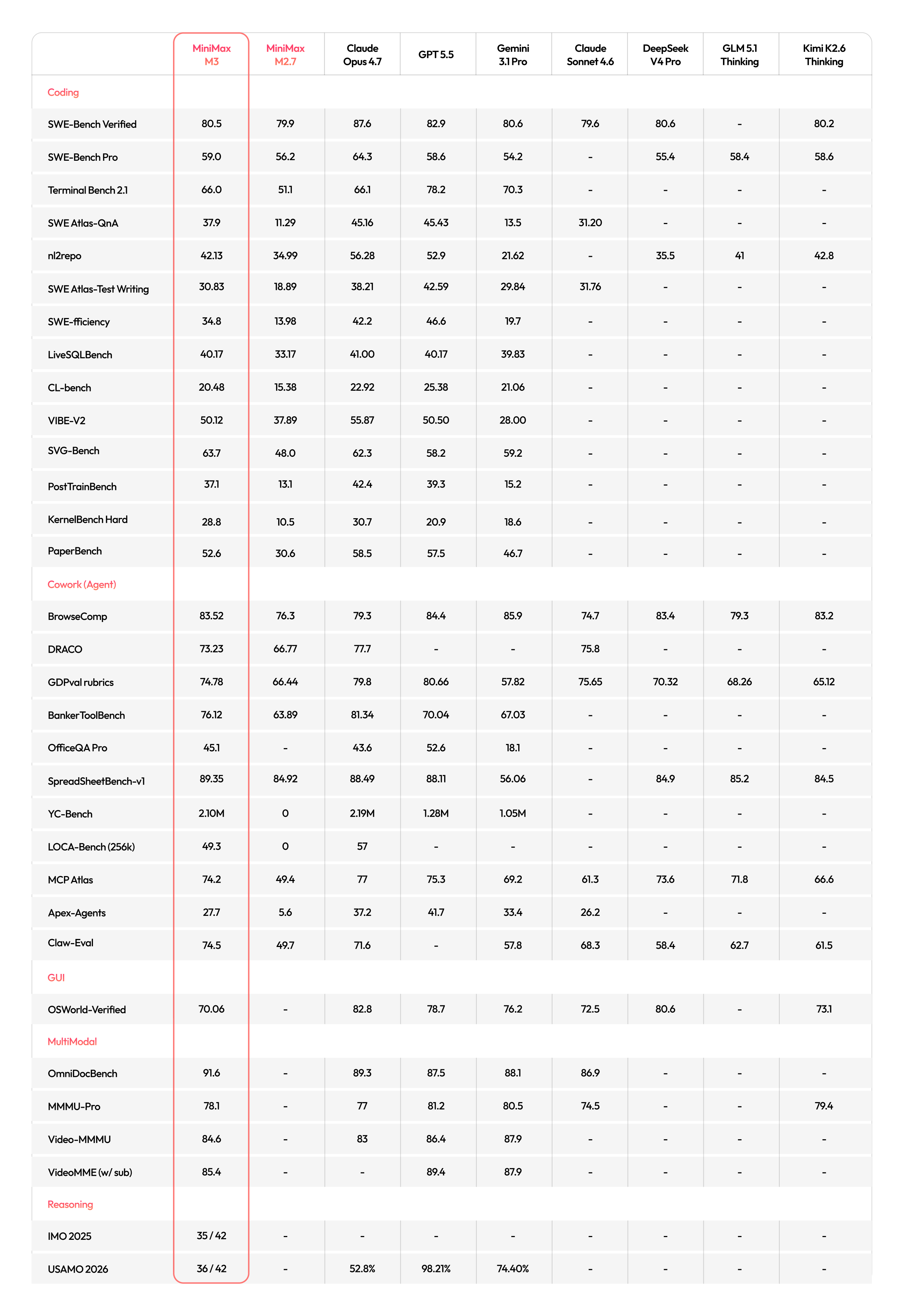
M3 全量评测对比表,9 个模型横向铺开。把视线放到 Opus 4.7 那一列,再放到右边开源三兄弟那几列。来源:minimax.io/blog/minimax-m3
故事全在这张表里。
编程主菜上,最能代表真实开发的 SWE-Bench Verified,M3 是 80.5——Opus 4.7 是 87.6,GPT-5.5 是 82.9,而开源同行 DeepSeek V4 Pro 也有 80.6、Kimi K2.6 是 80.2。换句话说,M3 在这一项上,跟它本该拉开差距的开源兄弟打成了平手,离 Opus、GPT 那一档还差着一整个身位。再看 SWE-fficiency(34.8 对 Opus 42.2、GPT 46.6)、GDPval、终端执行这些最主流的编程 / Agent 硬指标,M3 普遍排在 Opus 和 GPT 后面。
(顺带说一句,MiniMax 这张表对标的是 Opus 4.7——而 Anthropic 就在几天前、5 月 28 日,刚发布了更强的 Opus 4.8。真正的天花板,比表上画的还要再高一截。)
V2EX 上有个老哥一句话,把这种"宣传和体验对不上"的落差说透了:
“评测没输过,实测没赢过。”
这话损,但点到了要害。M3 当然有赢的地方——SVG 生成、文档解析、端到端 Agent 这几项它实打实拿了第一;可一旦把全表摊开、把真正的同行请进来,在最要命的那几项主流编程评测上,它就再难甩开谁。它的真实身位,不是官方通稿里"逼近 Opus"那个旗舰相邻位,而是稳稳卡在国产开源第一梯队的中游,和 DeepSeek、GLM、Kimi 这帮兄弟挤在同一条板凳上。
说句公道话,这不丢人,甚至是进步。比起自家的 2.5 和 2.7,M3 是货真价实的一次大跨步;MSA 是真创新;SVG 生成、文档解析(OmniDocBench 91.6 是全表最高)、端到端 Agent 这几个点上它是真的能打。
所以 M3 不是垃圾。它是一个扎实的、有真本事的中游选手,问题在于 MiniMax 想卖给你的是一个旗舰的价签。而它的"真本事”,还真有两件拿得出手的——这是我想先替它说的公道话。
三、先把话说回来:它真不是花架子
把全表的冷水泼完,得给 M3 一个公道。因为有两件事,是它实打实做到、大部分模型做不到的——不是 benchmark 上多零点几个百分点,是那种需要"坐得住"的长程硬仗。
第一件,是让 M3 独立复现一篇论文。MiniMax 丢给它的是一篇拿了 ICLR 2025 杰出论文奖的硬核工作《Learning Dynamics of LLM Finetuning》,研究大模型微调时的"学习动力学",要它从零把实验跑出来。M3 自主跑了将近 12 个小时,期间提交 18 次 commit、画出 23 张实验图,最后不光复现了论文里 SFT 阶段的预测概率变化趋势,还观察到了 DPO 实验里的"挤压效应",连原文提出的缓解办法都验证了一遍。这中间,多模态用来读懂论文里的曲线和公式,1M 长上下文保证论文、代码、实验日志能一次性全塞进去,编程和 Agent 能力负责把活干完——三样能力第一次在一条长任务里真正咬合上了。
第二件更能说明问题。MiniMax 让 M3 去优化一个 CUDA 算子:英伟达 Hopper 架构上的 FP8 矩阵乘法,是大模型推理里最难啃、资深工程师手写都要一两周的硬骨头。给它的只有一份任务描述、一个评测脚本,外加一个跑都跑不起来的代码骨架,没有任何现成的高性能实现可以抄。M3 连续干了大约 24 小时,提交 147 次、调用工具 1959 次,把硬件算力利用率从最初版本的 7.6% 一路逼到 71.3%,相对初版提速 9.4 倍。
最值得记住的是过程里一个细节:官方说,除了 Opus 4.7 和 M3,其它模型基本在前 30 次提交就没辙、自己退出了;而 M3 的最优解,出现在第 145 次提交——在那之前,它撞过好几次"怎么改都不动"的性能平台期,却没放弃,换着方向接着试。
这种"撞墙了还接着试一整天"的长程耐力,是 M3 真正的高光。它和上一章"实测没赢过"并不矛盾:M3 不是不行,是它的强项藏在那些需要一整天、几百次迭代才显出来的地方,而不是你早上随手丢三道题就能感受到的地方。
记住这个反差。因为下一章,你会看到它的另一面。
四、雷霆大思考:实测是什么样子
benchmark 是考场,实测是工地。两者经常对不上。
发布当天,国产社区已经有人上手了。有位测评的老哥给的标题特别传神——“进步了,但雷霆大思考”。

社区实测:M3 拓展到 1M、有了多模态,“能力还算说得过去”,但"中等偏下,和半年前的 GLM5 打个平手"。来源:locdd.com 社区
他的原话是这样的:
“今天早上测这么几道题给我截断了一万次。思考效率比 DeepSeek 都差,经常是思维链吃满 output token 就断了。”
“相比自家的 2.5 和 2.7 进步卓著……能力实际来说中等偏下,和半年前的 GLM5 打个平手。”
“雷霆大思考"这四个字,是这次实测最值得记住的吐槽。意思是 M3 答题时特别爱想,思维链(模型把推理过程一步步写出来的那段内容)拉得又臭又长,经常还没想到答案,就把这一轮的输出额度(output token)给写满了,然后——啪,断了。你以为它在深思熟虑,其实它在原地烧稿纸。
这个毛病单看是体验问题,但它和后面的账单是连着的。因为输出 token 是要按量收费的,而且是模型里最贵的那部分。一个爱写长思维链、还经常写到一半断掉的模型,意味着你每问一个问题,都在为它的"雷霆大思考"反复付费。参数规模上去了、token 烧得更快了,这笔账,最后是用户买单。
至于那句"和半年前的 GLM5 打个平手”——智谱的 GLM-5 是今年 2 月发布的旗舰,744B 参数、MIT 协议开源、白送,编程能力当时就逼近了 Opus 4.5。一个 6 月发布的新旗舰,实测被按在一个开源了快四个月、还不要钱的模型旁边比,这本身就说明了它的真实身位。
五、账单按米其林收:把涨价包装成促销
来到这篇最该讲清楚的地方——钱。因为 MiniMax 这次最敏感的动作,全在定价上。
很多人这两天在转一个数字:“M3 才 0.3 刀输入、1.2 刀输出,真便宜!"——先别急着高兴,这个价是有时效的。我们看官方自己那张定价表:

M3 官方 API 定价。注意标准价那一栏,和最底下那行小字。来源:minimax.io/blog/minimax-m3
M3 的标准价(512K 以内)是:输入 0.60 刀 / 百万 token,输出 2.40 刀。512K 到 1M 的长上下文档位,直接翻倍到 1.20 / 4.80。底下那行用小字写的”≤512K — 50% off for 7 days"才是关键:网上传的 0.3/1.2,是只持续 7 天的开业五折。七天之后,价格自己变回 0.60/2.40。
这是典型的零售刺客手法。用一个限时半价做锚点,让你以为占了便宜,等你把工作流迁过来、习惯养成了,促销一过,原价生效。开业大酬宾,过期恢复门市价,跟健身房卖年卡是一个套路。
而"原价"是什么概念,得放进 MiniMax 自家的历史里才看得清。从 M2 一路到 M2.7,它的标准 API 价格一直钉在 0.30 输入 / 1.20 输出,雷打不动:
| 模型 | 标准输入价($/M) | 标准输出价($/M) |
|---|---|---|
| M2 / M2.5 / M2.7(标准档) | 0.30 | 1.20 |
| M2.7 高速档 | 0.60 | 2.40 |
| M3(标准档,≤512K) | 0.60 | 2.40 |
| M3(512K–1M) | 1.20 | 4.80 |
看清楚这张表的门道了吗。M3 的标准价 0.60/2.40,输入和输出都是上一代标准价的整整两倍。而 0.60/2.40 这个数你应该眼熟——它恰好就是上一代 M2.7 那个要加钱才买得到的"高速档"价钱。以前你想跑得快才多掏的钱,现在成了 M3 的起步价。
至于全网在传的 0.30/1.20?那只是 7 天 5 折之后的临时数字。说穿了,这个"五折促销"不过是把价格暂时打回上一代的标准水平,让你先尝个甜头,七天一过,自动翻倍。长上下文那一档更狠,0.60 翻到 1.20、2.40 翻到 4.80,直接是老标准价的四倍(而且目前还是限时限量开放)。
这种"模型一变大、价格就跟着翻"的剧本,前不久 DeepSeek V4 Pro 才刚演过一遍:庞大的参数体量压上来,上线价格比前代跳了一大截,贵到挨了一轮骂,后来靠紧急降价才找补回来。参数上去、成本上去、“性价比"招牌松动,是一条已经有人走过的路。M3 这次,是 MiniMax 版的同一个故事。
订阅套餐(Token Plan)那边,是另一种更隐蔽的涨法。
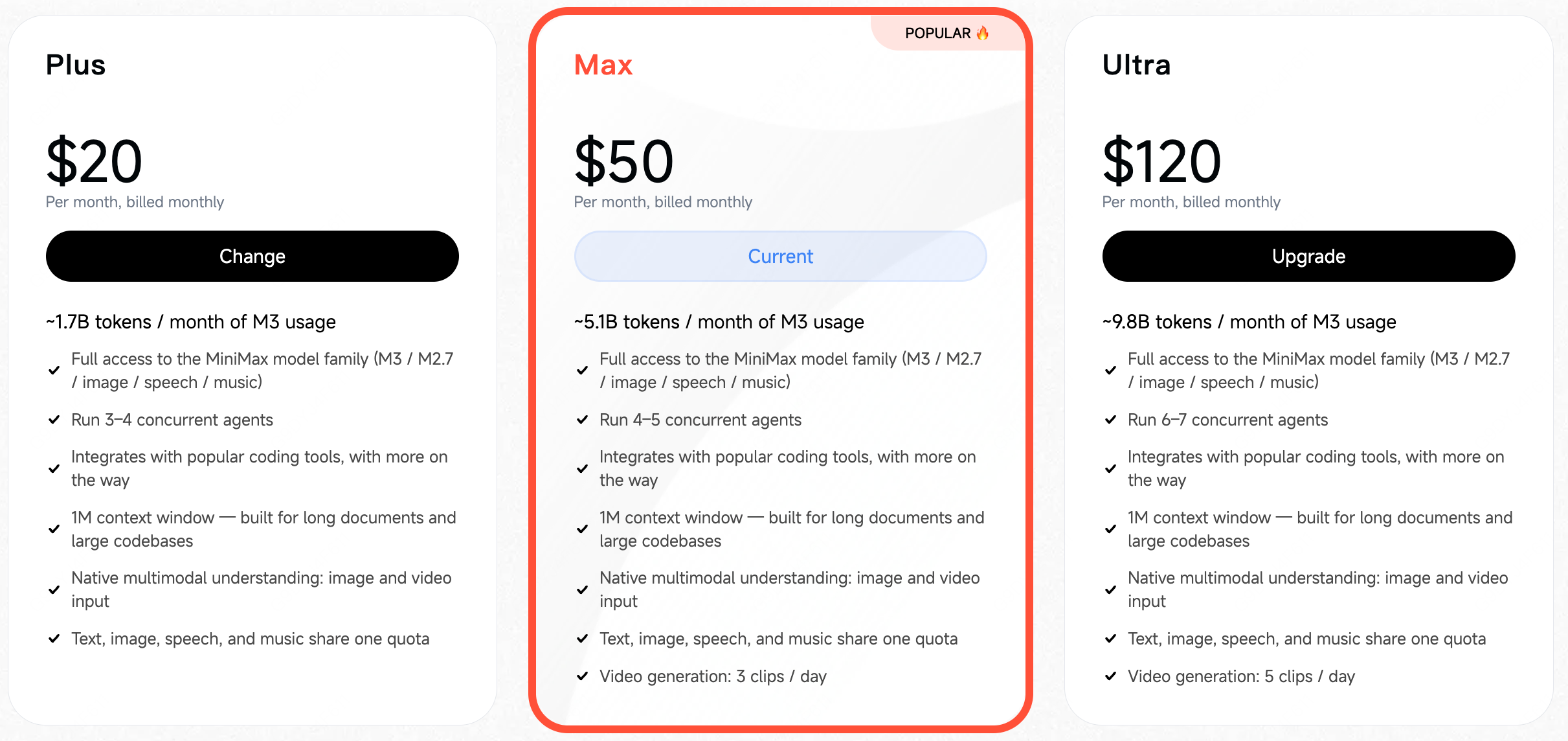
M3 的 Token Plan 三档订阅(国际版):Plus 20 刀约 17 亿 token,Max 50 刀约 51 亿,Ultra 120 刀约 98 亿,全模态共享额度。来源:platform.minimax.io
国内订阅页那边,社区转述的三档大致是 ¥49 约 6 亿 token、¥119 约 18 亿、¥469 约 55 亿。月费数字看着没涨,但社区给这次调价起了个名字,叫"套餐变相涨价”。变相在哪?老的 Coding Plan 是按请求次数算的:多少次调用 / 每 5 小时,跟模型多大没关系。新的 Token Plan 改成了按 token 量算。配上 M3 这个参数更大、思维链更长、动不动"雷霆大思考"的吃 token 大户,同样的钱,现在烧得比以前快得多。月费没动,但对长思考、长上下文、重度 Agent 这些场景,同一笔钱实际能跑完的活很可能不如从前——这就是"变相"二字的来历。
一句话总结这一章:MiniMax 把一次涨价,包装成了一次促销。
六、自带的那把刀:MiniMax Code,对标的正是 Claude Code
M3 这次没光发模型,还配了把专用的刀——MiniMax Code,一个为 M3 量身训练的 Agent 工具。
这里得先把"Harness"这个词讲明白,因为它现在是评价模型时绕不开的变量。Harness 指的是承载大模型去干 Agent 活的工程框架——Claude Code、Codex、Gemini CLI 都是 Harness。同一个模型,套在不同 Harness 上,表现能天差地别。我自己就有体会:同样是 GLM-5.1,跑在 Claude Code 里的编程能力,明显强过跑在别的框架里。在 Agent 时代,Harness 是模型真正的入口,模型再强,没有趁手的 Harness 也使不出力。
所以 MiniMax 自己下场做 Harness,方向是对的。更有意思的是它的对标对象——官方博客里白纸黑字点了名:
“我们注意到 Claude Code 最近也发布了方向类似的 Dynamic Workflows。相比 Claude Code 更强调基于 JS 代码的固定编排,MiniMax Code 更专注于’深度反思与持续纠错’。”
这句话我读着格外有感触。因为上周我刚拆完 Claude Opus 4.8,里头最重的篇幅就是给它那套 Dynamic Workflows——用 JavaScript 把多个子 Agent 的协作写成确定性的脚本。转头 MiniMax 就在发布会上点名要走一条不一样的路:不写死的脚本,而是让 Agent 团队(Agent Team)边干边反思、实时调整计划,靠一个"生产者 + 验证者"(Producer + Verifier)的对抗循环自我纠错,号称能无人值守连干好几天。再加上 M3 的原生多模态,它还能直接操作电脑。官方举的例子是:你在手机上说一句"帮我打开本地 ERP,照着这张 Excel 批量录发票",它就跨应用把活干了。
听上去很美。底层还很厚道——MiniMax Code 是基于开源项目 OpenCode 和 Pi 搭的,官方说将来也打算把它开源回馈社区。模型权重和技术报告,也承诺在发布后约 10 天放出。这些都是加分项,是 MiniMax 一贯的开源人设在撑着。
但理想和现实之间,隔着一个"能不能用"。还是 V2EX 那个聊"变相涨价"的帖子里,有人补了一刀:
“有了自己的 code agent 工具,MiniMax Code。但是太草台班子了,官网点击下载没有反应。”
一把对标 Claude Code 的刀,发布当天官网的下载按钮点了没反应。这就是 MiniMax 的某种缩影:想法和方向都对,benchmark 和愿景都漂亮,落到"用户真能不能顺畅用上"这最后一公里,总差一口气。
七、那么,这台水桶机到底卖给谁
泼了这么多冷水,得给个公道的结论:M3 不是不能买,是看你是谁。
如果你是这几种人,M3 真有它的位置:
- 你需要那 1M 上下文。整库代码理解、超长文档解析,M3 的 MSA 把长上下文的成本压下来了,这是它的硬长板,闭源旗舰跟你按豪华价收,它至少便宜。
- 你要多模态,又不想付旗舰价。图、视频、文档一把抓,M3 在这一档的性价比是真实的。
- 你是 Pay As You Go 的轻度 / 创意用户,追求情绪价值和够用就行,不追求绝对性能。这类场景我自己就把一部分 ComfyUI 工作流从 Gemini Flash 换成了 DeepSeek V4 Pro——逻辑一样:中等性能 + 能接受的成本 + 够用的生态,就行。
但如果你是冲着"便宜"来的老 MiniMax 用户,或者你是个重度编程用户——那 M3 大概率会让你失望。冲便宜的,会发现招牌已经被锯了;重度编程的,会发现它实测追不上 Opus,甚至追不平价格更狠的开源同行,而你为它的"雷霆大思考"付的 output token 账单,正在悄悄变厚。
收尾:护城河不在"全面",在"便宜"
回到开头那家沙县小吃。
M3 这一步,本质是一场豪赌:MiniMax 想用"全面"(1M、多模态、前沿 coding 三合一)换掉自己"便宜"的旧人设,从街角小吃往米其林挪一挪。技术上它确实够到了"唯一一个三合一开放权重模型"的名头,MSA 也是真东西。
可它赌错了一样东西。在这个 Opus、GPT、Kimi、GLM 神仙打架的市场里,MiniMax 唯一守得住的护城河,从来不是"全面"(全面它打不过旗舰),而是"便宜"。现在它亲手把这条长板锯了,去拼一个自己并不占优的"全面"赛道,结果就是一台标准的水桶机:样样及格,样样不顶尖,而那块本可以让它鹤立鸡群的便宜,没了。
它真正要面对的对手,甚至不是 Opus。是那个今年 2 月就开源、MIT 协议白送、编程跟它有来有回的 GLM-5(更新一档的 GLM-5.1 还在 MiniMax 自己的对比表里跟它咬着);是 Kimi K2.6,是占着性价比中游位置的 DeepSeek V4 Pro。当同行又强又开源又便宜,一台样样及格、价格还倒涨一倍、自带的刀连下载按钮都点不动的水桶机——
它到底要卖给谁?
这个问题,我猜 7 天促销结束那天,MiniMax 自己会先收到答案。
主要来源
本文的事实、定价与 benchmark,来自 MiniMax 官方博客与定价页、第三方平台,以及社区一手实测,涉及来源包括:
- 🚀 MiniMax M3 官方博客、模型页与 API / Token Plan 定价页
- 📊 OpenRouter 等第三方平台定价
- 📰 V2EX、LINUX DO、大佬说(locdd)的社区实测与讨论
- 📄 Anthropic、DeepSeek 等竞品官方资料