论文实战 · PolyKV:多个 AI Agent 怎么共用一份压缩 KV,把显存从爆炸压成一条平线
让一群 AI Agent 一起干活,有个浪费大得离谱、却一直被默默忍着的地方。
它们分工不同,一个写代码、一个查资料、一个跑测试,可常常要读同一份背景资料,比如同一份项目文档,或者同一段长长的系统提示。按现在主流的做法,每个 Agent 都在自己的显存里,把这份一模一样的资料原样存了一整份。十个 Agent,就是十份一字不差的重复。这些副本谁也不会去改,纯粹是同一坨数据被抄了十遍,显存就这么被撑爆了。
四月挂上 arXiv 的一篇论文 PolyKV,要治的就是这个浪费:那份大家都要读的资料,只留一份,压一下,所有 Agent 共用。论文给的卖点挺漂亮:Agent 越多省得越狠,那份共享缓存的显存开销几乎不随人数涨,单份缓存还能再压掉将近三分之二的体积,质量却几乎不掉。
这篇文章想做两件事。先把 PolyKV 这套"共享加压缩"到底怎么运转讲透,让你看完能自己跟人复述清楚。然后我照着它的方法,在一张二手矿卡上从零写了一遍、亲手跑了一遍,告诉你它真跑起来什么样,以及上手时有哪两个跑通了才知道的门道。
作者把代码开源了,这点值得提一句。我没直接跑他的代码,而是照论文的方法独立实现了一遍。不是信不过他,是只有自己从零搭一遍才能真正摸清每个环节,也才能把那些正文一带而过、其实挺关键的地方替你拎出来讲明白。
一、先讲清楚那份"中间结果":KV 缓存,一个吞显存的无底洞
要看懂 PolyKV 在省什么,得先认识它对付的那个吃显存大户,KV 缓存。
你跟大模型对话,它是一个字一个字往外蹦的。每蹦一个字之前,模型都要回头看一遍前面所有的字,才知道接下来该说什么。问题是,“回头看一遍"这件事很贵。要是每蹦一个字都把前文从头算一遍,算力根本扛不住。
于是有了一个偷懒的办法。模型每读进一个字,就顺手为它算好一对向量,一个叫 Key,一个叫 Value,然后存起来。你可以把它想成给每个字做了一张索引卡:Key 是这张卡的"标签”,负责被后面的字检索;Value 是卡上记的"内容",检索到了就把内容取出来用。有了这一摞卡,模型蹦下一个字时不用重算前文,翻卡就行。这摞卡,就是 KV 缓存。
省了算力,代价是吃显存,而且吃得有规律:上下文每长一个字,就多一张卡,缓存线性地涨。一段几千字的长文喂进去,这摞卡能轻松占掉好几个 GB 显存。
单个对话顶着几个 GB 已经够呛了。真正要命的是开头那个场景:一群 Agent 围着同一份文档干活。这份文档对应的那摞卡,本来是同一摞,但按传统做法,每个 Agent 都得在自己手里存一份完整拷贝。五个 Agent,就是五摞一模一样的卡;十五个 Agent,就是十五摞。显存的账,就是这么一摞摞重复堆上去爆掉的。
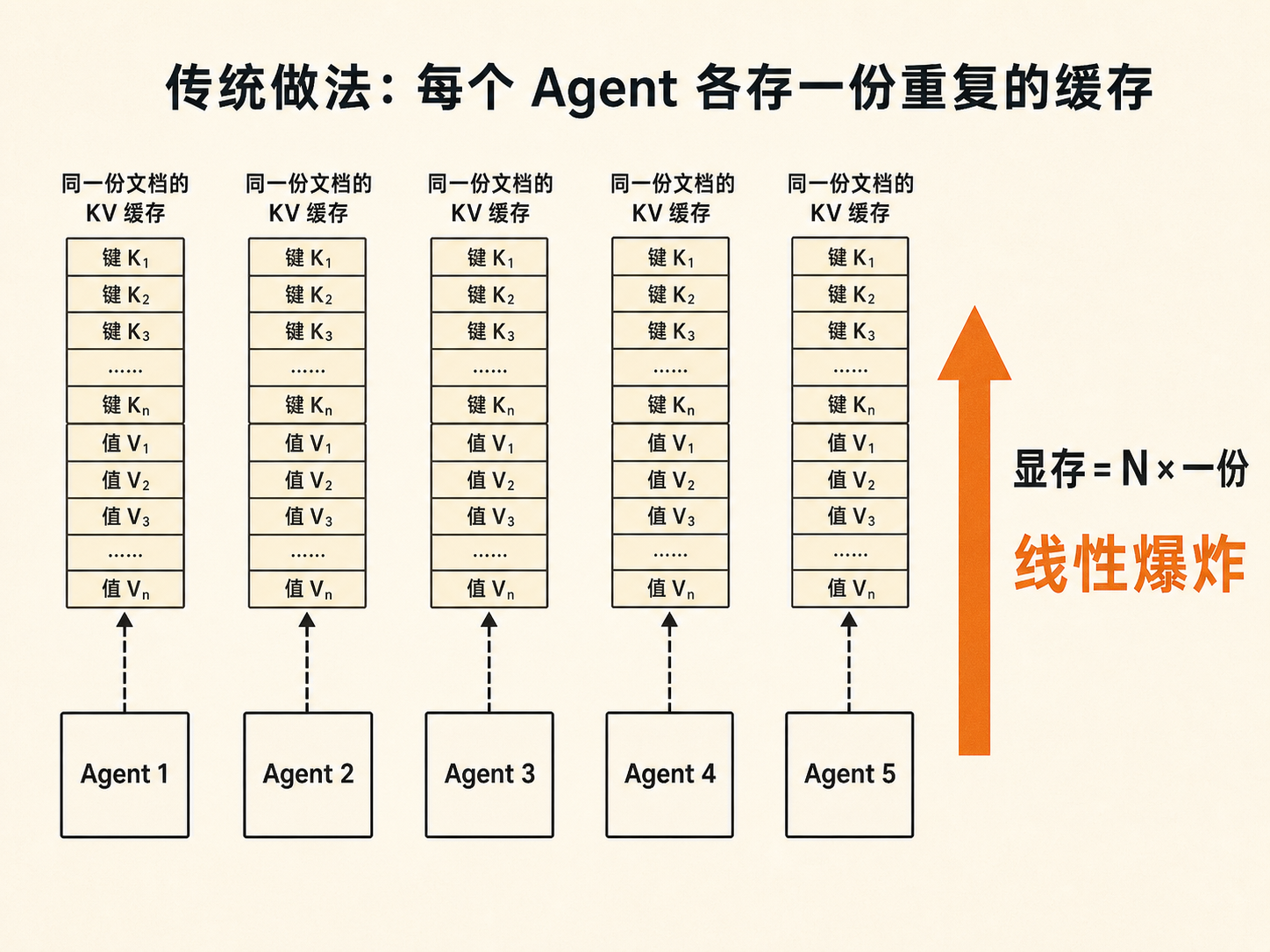
传统做法下,每个 Agent 都为同一份文档存一份完全相同的 KV 缓存。Agent 越多,重复的拷贝越多,显存随人数线性往上堆。
这就是 PolyKV 要解决的浪费:那摞卡,每个 Agent 手里的明明一模一样,凭什么每人各存一整份。
二、PolyKV 的解法:压扁,只留一份,大家共用
PolyKV 的 idea 一句话能说完:那摞大家都要读的卡,只留一份,压扁了存进一个公共的地方;哪个 Agent 要用,就从这一份里临时取出来、还原成自己能用的样子。
论文管这个公共的存放处叫共享池(SharedKVPool)。它的工作方式分两步,特别符合直觉。
第一步,压一次。一份共享文档进来,PolyKV 把它那摞 KV 卡压缩好,存进共享池。这件事只做一次,不管后面有多少个 Agent 要用。
第二步,按需解压。某个 Agent 轮到处理这份文档了,它不自己存卡,而是从共享池里把压缩数据取出来,临时还原成一份自己能直接喂给模型的缓存,用完即弃。
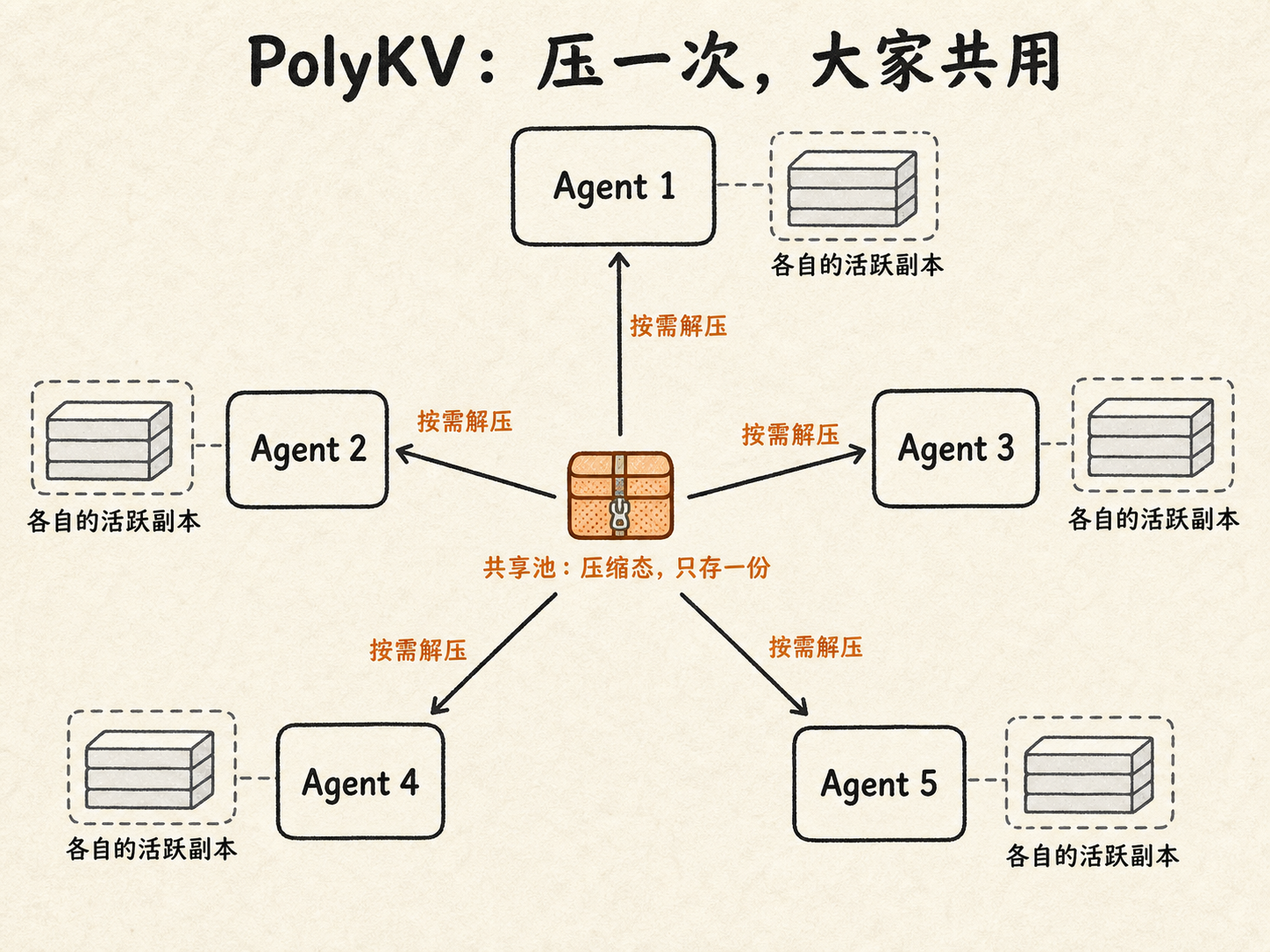
PolyKV 把共享文档的缓存压缩好、只存一份放进共享池。哪个 Agent 要用,就按需解压出一份自己的活跃副本,用完即弃。
差别就在这里。传统做法是"N 个 Agent,N 摞完整的卡";PolyKV 是"一份压缩的卡躺在池子里,谁用谁临时解压一份"。压缩省的是单份的体积,共享省的是重复的份数。两刀下去,账面上的显存才能从随人数线性增长,被摁成一条几乎不动的平线。
听到"压缩"你可能立刻警觉:压了还能用吗,模型会不会变傻?这正是 PolyKV 最讲究的地方,也是下一节的主角。
三、最讲究的一步:为什么 Key 压得轻,Value 压得狠
PolyKV 压那摞卡时没有一视同仁。它把 Key 和 Value 分开处理,一个压得客气,一个压得狠。这个"区别对待"就是论文标题里那个"非对称"(asymmetric)的由来,也是整套方法最巧的地方。
先说为什么要区别对待,还是回到索引卡。Key 是标签,要被拿去和别的字做匹配、算出"该关注谁"的注意力分数。这个分数算完还要过一道 softmax,而 softmax 有放大效应,标签上错一点点,放大之后可能就匹配错了人,整个输出跟着崩。所以 Key 是敏感件,碰不得。Value 是卡上的内容,命运温和得多,只是被一堆权重加权求和、平均一下。平均这种操作天生抗噪,里头个别数值糙一点,混在一起就摊匀了。一个怕错,一个耐糙,那就该区别对待。
Key:客气地压一半。 Key 用的是最朴素的 int8 量化,原本一个数值用 16 位浮点存,现在硬塞进 8 位整数里。做法很直白:找出这摞 Key 里绝对值最大的那个数,拿它定个缩放尺度,把所有数按这个尺度等比例缩到 -127 到 127 的整数范围。位宽从 16 砍到 8,体积减半,精度损失有限。敏感件,点到为止。
Value:往死里压,压到 3 位。 Value 用的是一套叫 TurboQuant 的方法,把 16 位压到 3 位。3 位是什么概念?一个数只能取 8 个值之一(2 的 3 次方)。怎么做到的,分三步。
第一步,旋转。先对 Value 向量做一次叫 FWHT(快速沃尔什-阿达玛变换)的操作。这名字唬人,但你只要记住它干的事:把一组数值"摊平打散",让原本东一个高峰、西一个低谷的分布变得更均匀更规整,像把一桌乱堆的菜重新摆盘。摆规整了,后面才好统一处理。
第二步,归位。锚点是预先设好的 8 个固定值,按标准正态分布算出来(论文里白纸黑字给了:±0.245、±0.756、±1.344、±2.152)。归位之前还有个关键的小动作:先把旋转后的数值缩放一下,让它的尺度和这套锚点对齐;对齐之后,再把每个数值就近归到离它最近的那个锚点上。这个"缩放对齐"看着不起眼,第五节你会看到,它就是整套方法的生死开关。
第三步,记编号。既然每个数都被归到了 8 个锚点之一,那就不用存这个数本身了,只存"它归到了第几个锚点"。8 个锚点,编号 0 到 7,正好 3 位二进制装得下。于是一个原本 16 位的数,最后只剩一个 3 位的编号。
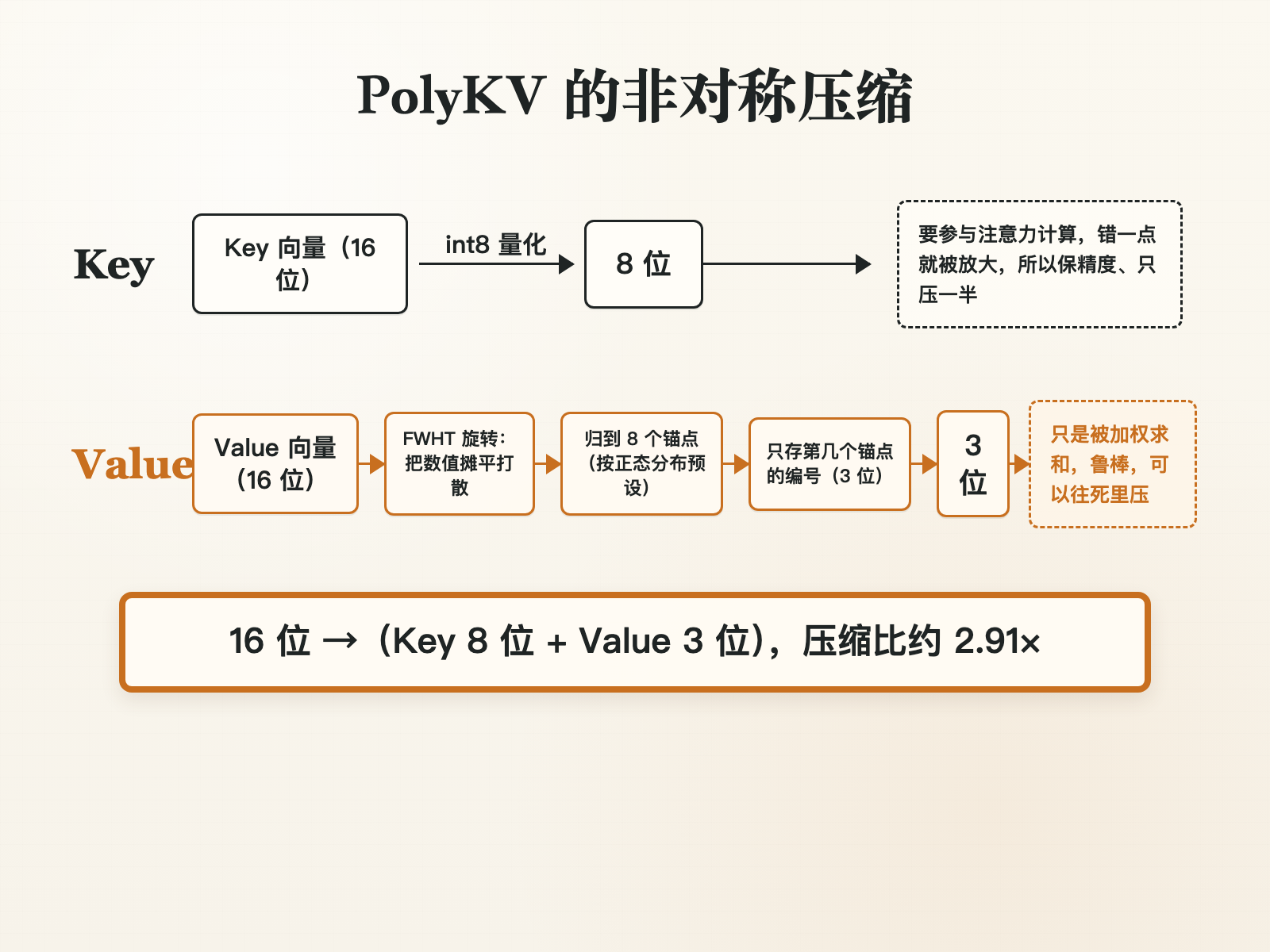
非对称压缩:Key 怕错,只用 int8 客气地压到 8 位;Value 耐糙,用 TurboQuant 经"旋转、归到 8 个锚点、记编号"三步狠压到 3 位。合起来压缩比约 2.91 倍。
把两边的账一算:Key 从 16 位到 8 位,Value 从 16 位到 3 位。合起来,压缩比是 (16+16) / (8+3),约等于 2.91 倍。再叠加"N 份变 1 份"的共享,省下的显存就很可观了。
到这里 PolyKV 的全貌就清楚了:共享省份数,非对称压缩省体积,TurboQuant 把 Value 这个耐糙的大头压到极致。设计得相当漂亮。
漂亮归漂亮,我还是想亲手跑一遍。一来想确认那个"压完几乎不变傻"是不是真的,二来我对那个"非对称"有点好奇:Key 重 Value 轻当然有道理,但它到底比"两边都老老实实 int8"好在哪、好多少,论文没明说。这种问题,跑一遍最干脆。
四、我亲手跑了一遍:显存确实被摁平了
讲完原理,该上手了。这一节我把实验台子整个摊开,你看完能自己复现。
模型我选了和论文作者同一个小家伙,SmolLM2-1.7B,数据用标准的 WikiText-2,取三段各 3072 个 token 的长文本当样本。规模故意压到最小,一张二手的 2080Ti 矿卡就能跑。这是这个栏目的规矩:选你家里那张卡也跑得动的规模,不然算什么"最后一公里"。
我设了三组对照,除了压缩方式不同,模型、数据、上下文、随机种子全部锁死一致:
| 组别 | 压缩方式 | 角色 |
|---|---|---|
| A | 不压(原始 16 位) | 基准线,质量的标尺 |
| B | PolyKV 非对称(Key int8 + Value 3 位) | 论文主角 |
| C | 对称(Key、Value 都 int8) | 我顺手加的对照 |
A 和 B 是必须有的。C 是我自己好奇加的:论文讲了非对称多巧妙,但没跑一组"两边都简单 int8"来比一比。我想看看那个被跳过的、土办法一样的对称压缩,到底差在哪。这组多出来的对照,正好帮我们把"非对称到底换来了什么"看清楚,第五节会用到。
先看显存。下面这张图是那摞共享文档的 KV 缓存占的显存,随 Agent 数量怎么变。
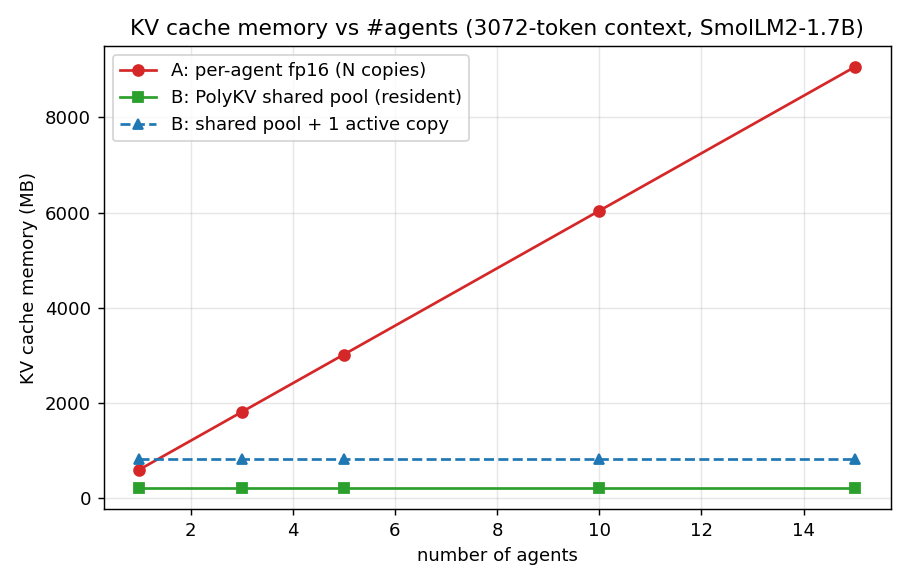
红线是传统做法每个 Agent 各存一份,从 1 个 Agent 的 604 MB 一路冲到 15 个 Agent 的 9060 MB。绿线是 PolyKV 压缩共享池,从头到尾就 212 MB,贴着地皮。
红线是传统做法。它从 1 个 Agent 的 604 MB,一路笔直冲到 15 个 Agent 的 9060 MB,是条朝天上去的斜线。绿线是 PolyKV 的压缩共享池,从头到尾就 212 MB,是平的。
把数字摊开说人话:十五个 Agent 共享一段三千 token 的文档,传统做法要 9 GB 显存,PolyKV 只要 212 MB。这不是省了一点,是把"共享文档的缓存开销随人数线性增长"这道一直在涨的账,焊死成了一个不随人数变的常数。
这里要说句实在话,免得你期待错。省掉的,是十几个 Agent 重复存同一份文档的那些拷贝;每个 Agent 真正轮到自己推理时,那份临时解压出来的活跃缓存,还是各算各的。所以这条平线针对的是"共享部分"的重复浪费,不是把整个多 Agent 系统的显存都变成常数。但对正在爆发的多 Agent 应用来说,把共享这块摁平,已经是真金白银的省了。
那质量呢?压成这样,模型变傻了没有?看下一张。
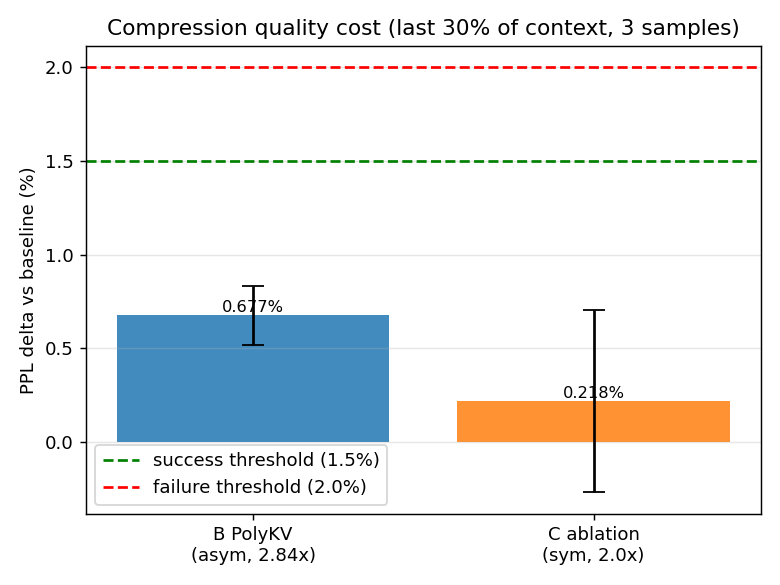
横虚线是我事先定好的判据:绿线 1.5% 算"成立",红线 2.0% 算"翻车"。蓝柱 B 非对称涨了 0.677%,橙柱 C 对称只涨 0.218%,两根都远在及格线以下。
这张图量的是压缩之后,模型对文本的"困惑度"(perplexity,可以理解成模型读下文时有多懵,越低越好)比基准线 A 涨了百分之几。两条横虚线是我事先定好的判据:绿线 1.5% 算"成立",红线 2.0% 算"翻车"。
蓝柱是论文主角 B 非对称,困惑度只涨了 0.677%。这个数说明模型基本没变傻,而单份缓存的体积省掉了约三分之二。论文那个核心卖点,省显存、质量几乎无损,到这里,在我这个最小复现的规模上,我亲手确认了:是真的。
如果故事到这就结束,这会是一篇标准的"论文复现成功"汇报。但你大概也注意到了,图里还有一根橙色的柱子,比蓝柱还矮。那是我顺手加的对称组 C,它带出了两个跑通了才知道的门道。
五、两个跑通了才知道的门道
门道一:那个让你直接翻车一百倍的开关
这个门道是我自己撞墙撞出来的,分享给你能省一下午。
回到第三节那个把 Value 压到 3 位的 TurboQuant。它要把每个数值归到 8 个锚点上,归之前有个前提:你的数据尺度得和锚点的尺度对得上。锚点是按"标准差为 1"的正态分布排的,要是数据尺度对不上,就会全归错地方。
那么这个对齐尺度的缩放,是拿一整块数据算一个统一的尺度,还是每一行单独算一个尺度?论文正文没细说。我图省事,按最自然的理解来,整块数据用一个统一尺度。
跑出来的结果,给我看傻了:
| 缩放方式 | 困惑度涨幅 | 能用吗 |
|---|---|---|
| 整块统一尺度 | +63.5% | 废了 |
| 每行单独尺度 | +0.677% | 能用 |
同一套算法,就因为缩放的颗粒度不一样,质量损失从 0.677% 暴涨到 63.5%,差了将近一百倍。前者是个语无伦次的废物,后者才是论文说的那个"几乎无损"。
我顺着这个反常去刨,刨到了病根。模型浅层的那些 Value 向量,经过 FWHT 旋转之后尺度小得可怜,第 0 层的标准差只有 0.05 上下。可那 8 个锚点是按标准差为 1 铺开的。拿一把为"标准身材"做的尺子去量"迷你身材",整块统一缩放时,浅层这些小数值会被锚点的间距碾成一团糊。只有每一行单独缩放,让尺子贴合每行自己的尺度,3 位量化才活得过来。
这里要替作者说清楚:他开源的代码里,是规规矩矩做了按行缩放的,每行都存了一个自己的尺度。所以这不是论文的错,作者自己跑得通。只是这个生死攸关的步骤,正文里讲得很轻,轻到一个只读正文、不啃代码的人很容易漏掉。我把它拎出来,是想帮你把这步钉死:上手 TurboQuant,缩放一定要按行来。这个坑我替你踩过了,那个 63.5% 的翻车日志我留着,能回查。
门道二:非对称买的是压缩比,不是质量
再说回那根比主角还矮的橙柱,我顺手加的对称组 C。
它的困惑度只涨了 0.218%,比论文主角 B 的 0.677% 还低,低了大概三倍。(BERTScore 那项两组差不多,对称 0.910、非对称 0.901,差距太小,这项分不出高下,就不细说了。)
把三组的账一起列出来看:
| 组别 | 压缩比 | 困惑度涨幅 | 一句话 |
|---|---|---|---|
| A 不压 | 1.0× | 0%(基准) | 标尺 |
| B 非对称 | 2.84× | +0.677% | 压得多,质量掉得多一点点 |
| C 对称 | 2.0× | +0.218% | 压得少,质量最稳 |
(顺便交代下这里的 2.84×。第三节那个 2.91× 是只算编码位数的理想值。实际跑起来,每行还得存一个缩放尺度,把这点开销算进去,真实压缩比是 2.84×。这正是门道一里"按行缩放"的代价,确实存在,但很小。)
这张表把非对称的真实面目摆出来了。它不是"又省又准"的免费午餐,而是一笔清清楚楚的交易:非对称的压缩比比对称高 42%(2.84 对 2.0),代价是质量损失大了三倍(0.677% 对 0.218%)。
所以非对称设计买到的,是更高的压缩比,不是更好的质量。我想强调,这不是说作者设计错了。在显存极度紧张、每一兆都要榨的场景里,多换来的那 42% 压缩是真有用的,非对称完全站得住。它只是被讲成了"更优解",而它实际的样子是"更激进的取舍"。
这也正好说明了那组对照的价值。一篇论文不可能把所有对照都跑全,作者把重心放在论证非对称为什么能工作,很合理。而"它比简单方案到底值不值"这个问题,需要有人补一组对照来回答。我顺手补了,答案就清楚地摆在表里,留给你按自己的场景挑。
六、给想上手的人的实在话
把这一趟收成几句能带走的。
PolyKV 的核心 idea 是成立的,我亲手验证过。多个 Agent 共用一份压缩的 KV 缓存,确实能把共享部分的显存从随人数爆炸压成一条平线;至少在我这个小模型、小规模的复现里,质量代价小到可以忽略。这个方向值得一试,作者也老实开源了代码,想深入的可以直接去读。
真要上手,我的建议是分两步走。先用对称压缩(两边都 int8)把你的多 Agent 共享池跑通,拿到 2 倍压缩加几乎零损失;至少在我这次小规模复现里,这是性价比最高、最省心的一步。等你确实需要那多出来的 42% 压缩了,再换上非对称的 TurboQuant,但一定记住那个门道:缩放按行来,否则等着翻车一百倍。
最后一句更通用的,送给所有想把前沿论文落地的人:正文和代码要配着读。正文给你结论和动机,告诉你"为什么这么设计";而真正决定你能不能跑起来的那几个细节,常常安安静静待在代码里,等你自己去发现。这次的 TurboQuant 按行缩放,就是这么一个细节。
这趟实验的全部代码、跑出来的数据、能一键复现的脚本,我都整理好了,一张消费级单卡就能跑。
一篇论文真正讲了什么、上手又是什么手感,光读摘要是摸不到的。得自己把它讲透,再亲手跑一遍。这就是这个栏目想干的事。
主要来源
- 📄 PolyKV 论文(arXiv 2604.24971)
- 🚀 PolyKV 官方代码仓库(作者开源实现,含复现入口)
- 🧪 本文的独立复现代码(单卡可跑,含 A/B/C 三组对照与全部原始运行日志,文中每个数字都能回查)
- 📦 SmolLM2-1.7B 模型与 WikiText-2 数据集